前言
这周做了一个新功能,就是全自动地把微信的语音文件给提取出来,然后转换成文字,一来是一目了然,二来是方便检索。未曾想到的是,在这个过程中,碰到了几个不大不小的坎,踩到了几个不深不浅的坑,在此逐一记录解决方案,供后来人参考。
想要体验这个功能,请参看这个链接![]()
定位微信语音文件
通过iOS应用逆向工程中提到的思路,定位微信的语音文件并不是什么难事。它们一般在
/WeChat Path/Documents/Random Serial/Audio/Random Serial/random.aud
发出或收到一条语音消息,都会产生一个.aud文件。因为aud不是常见的后缀,我们不知道该用什么方式来播放这条语音,那么就先百度一下看看吧。
分析微信语音文件的格式
百度结果很多:
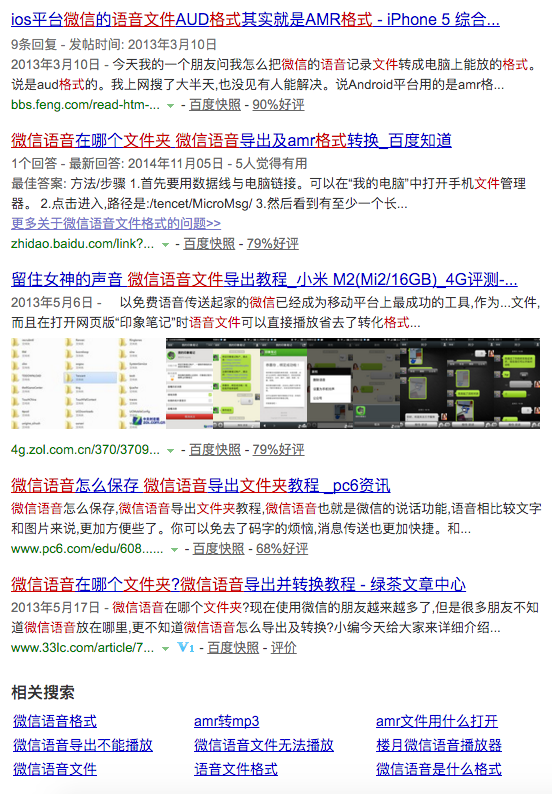
可以看到,大多数的帖子,都提到微信语音是amr格式的。其中这个帖子说,aud就是少了amr文件头的amr文件,只需要在文件开头加上amr标识就可以了:
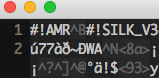
但是我发现,添加了amr头部的aud文件,还是不能用OSX自带的preview功能播放:

而正常情况下,preview是可以播放amr文件的。这说明,添加了amr标识的文件,并不能被preview正确识别;而这多半是aud文件的问题——它不是amr文件。
我把刚才的aud文件用MacVim重新打开,发现除去我们自行添加的amr头部之外,aud本身含有一个
#!SILK_V3
字样的标识。虽然我对音频编码和文件格式不甚了解,但既然amr文件的头部标识是以#!开头,那么我推测#!SILK_V3应该也是一个文件头。Google之:
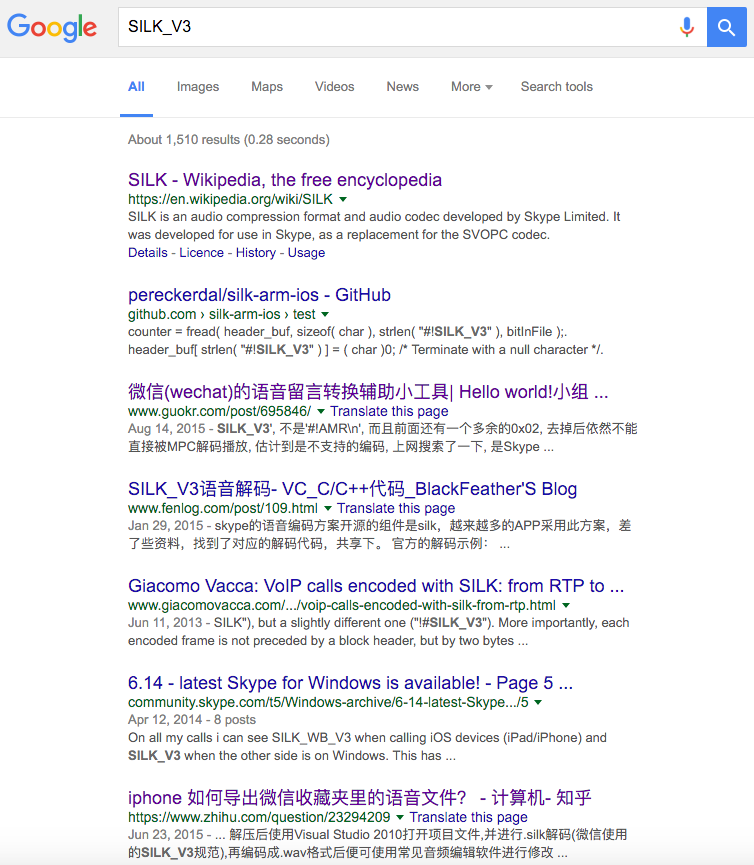
这样的话,我们基本可以确定微信的语音文件,就是 变种的 silk文件了,我们需要把它修改为纯正的silk文件。为什么说是变种呢?马上就知道了![]()
生成纯正的silk文件
根据果壳网友NetCharm的分析:

微信在aud文件的最开始添加了1个字节,如果把这个字节删掉,这个文件就是一个纯正的silk格式文件。他编译了一个decoder.exe,可以把silk文件给转换成pcm文件;但是我用的是OSX,无法执行exe文件。好么,继续寻找解决方案,把silk文件转换成pcm。
把silk文件转换成pcm文件
又是一顿Google,找到了这篇文章,博主的目的跟我类似。按照他的操作,先用HomeBrew安装ffmpeg:
brew install ffmpeg,然后从GitHub上下载SILKCodec工程(值得一提的是,这个工程的主人是一个中国开发者,音频处理达人,我也已经跟他取得了联系,请教一些音频技术上的问题![]() ),然后在
),然后在SILK_SDK_SRC_ARM里先make lib,再make decoder,即可生成OSX上的命令行工具decoder。对纯正的silk文件执行命令:/path/to/decoder /path/to/silk path/to/pcm,即可生成pcm文件。
2016.7.21编辑:
还可以用这个静态库将silk转化成pcm,@hangcom 亲测可用。
把pcm文件转换成wav文件
根据刚才那篇博文,用博主的脚本就可以把pcm文件转换成wav文件,而他的解决方案正是ffmpeg:
ffmpeg -f s16le -ar 24000 -i /path/to/pcm -f wav /path/to/wav
播放此wav文件,听到的就是我在微信里发出的语音消息——
“定期整理用户昵称中含有的手机号、用户名、公司。”21.wav (267.3 KB)
用科大讯飞SDK解析wav文件
从这里下载讯飞的官方iOS demo(注意勾选“语音听写”),在下载的工程中打开“MSCDemo → MSCDemo → business → isr → IATViewController.h”,其中的pcmFilePath即是音频文件的路径。
在IATViewController.m中的第42行,将pcmFilePath改为wav文件的地址,然后点击下图的“音频流识别”:

即可快速测试解析功能(注:讯飞iOS SDK仅支持pcm和wav格式的音频文件):

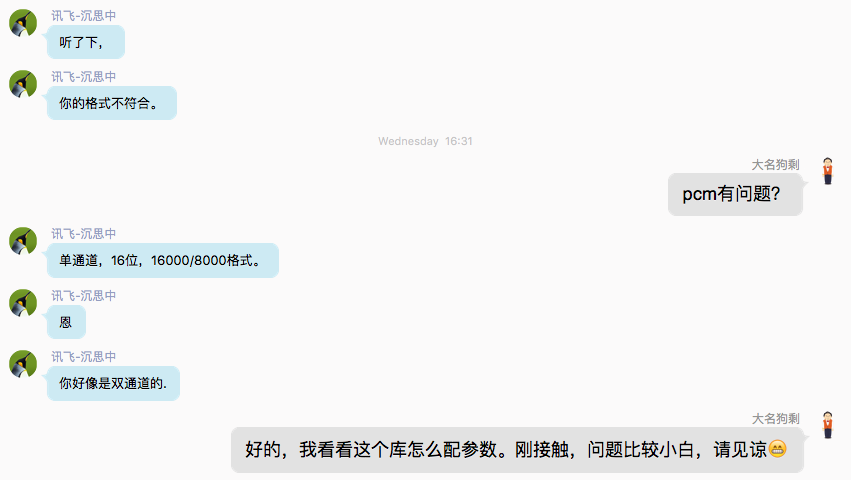
对比上面的wav文件,可以看到解析的偏差很大。因为讯飞的中文语音识别技术已经是全球领先的了,所以不大可能会出现这么大的识别错误。问了下讯飞的技术人员,得知问题可能在这些方面:
好了,继续研究,看看怎么处理。
进一步处理pcm
经张总@NavilleZhang
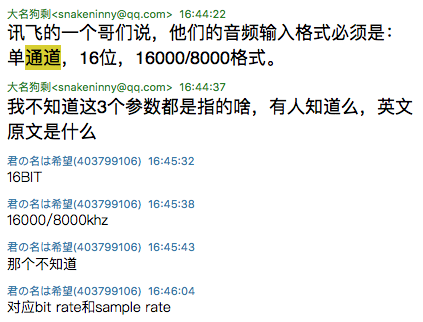
和爱拍的CTO指点:
![]()
得知讯飞哥们提到的“单通道,16位,16000/8000”各指的是channels、bit rate/sample size和sample rate。它们在ffmpeg里对应的设置方式分别是-ac channels、-b:a bitrate、-ar rate。我们来试试看:
ffmpeg -f s16le -ar 24000 -i /path/to/pcm -f wav -ar 16000 -b:a 16 -ac 1 /path/to/wav
识别效果如图:
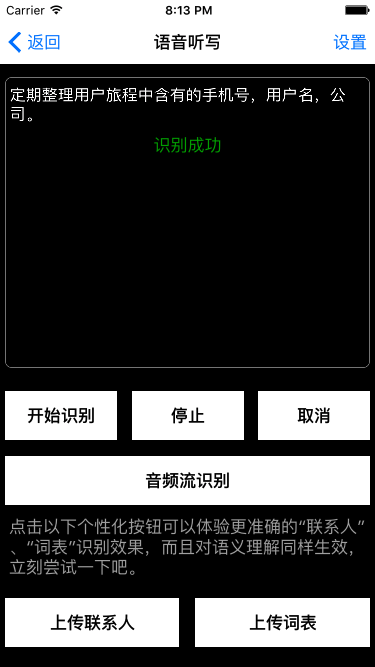
识别得几乎没有问题了。
误打误撞
因为在上面的识别中,“昵称”被听成了“旅程”,还是有些不爽,于是我又擅自改变ffmpeg的参数,想看看能不能做到100%识别准确。最后发现,按照如下的参数配置,识别率是最高的:
ffmpeg -f s16le -ar 12k -ac 2 -i /path/to/pcm -f wav -ar 16k -ac 1 /path/to/wav
但是,对于这个事实,我只知其然,不知其所以然,还请懂行的高手赐教![]()
在iOS中全自动完成上述操作
总结上面的操作,大致的顺序是:
- 获取微信语音aud文件;
- 去掉aud文件的第一个字节,将其转换为silk文件;
- 用silk decoder将silk文件转换为pcm文件;
- 用ffmpeg文件将pcm文件转换为wav文件;
- 用讯飞iOS SDK将wav文件转换为文本。
这5步我已经在OSX上用半自动的方式完成了,那么要在iOS中全自动完成,需要做到的,也是5步,与上面一一对应:
- hook微信中接收语音信息的函数(提示:这个函数所在的类,是以
Mgr结尾的),从中获取aud文件; - 用
NSMutableData处理aud,生成silk; - 这里有网友修改过Makefile文件的silk decoder for iOS,把Makefile中的iOS SDK路径作适当调整,即可编译出iOS上的decoder;值得一提的是,这里的decoder版本是1.0.8而不是最新版的1.0.9;1.0.9的源代码,用1.0.8的Makefile编译会报错失败,具体原因仍待进一步研究。
- BigBoss源有现成的ffmpeg二进制文件下载;还值得一提的是,iOS 9上通过system()或者posix_spawn()执行命令行工具会碰到一些坑。要解决它们,用到的关键词主要有:沙盒、ldid、RocketBootstrap。
- 讯飞SDK的集成比较简单,用到的主要是
[IFlySpeechRecognizer writeAudio:]及其回调函数。
至此,iOS全自动化解决方案的骨架已经出来了,剩下的肉,就留给各位看官自己来填吧![]()
谢谢阅读~
参考:
延伸阅读:
《实战:把微信语音转换成文字的全自动化解决方案(第二弹)》



 早知道我就直接调用微信的接口了
早知道我就直接调用微信的接口了