基础好啊,基础才好入门啊 ,哈哈
入门了才好撸高级的哈
zhang总你说是不是?嘎嘎
知识已经没有了盲区,我已经来到了知识的荒原。。看到Kaleidoscope添加控制流了,也就是if和for。里边提到一个API叫做PHI,硬着头皮学了一波。
首先学了一个词叫做SSA, Static single assignment,翻译过来叫静态单赋值,很肤浅的理解就是:
每个变量只能被赋值一次。
比如说
int a ;
if(xxx){
a = 1;
}else{
a = 2;
}
int b = a;
这种最后编译出来的IR里,a其实是用两个(甚至以上)变量来表示的
a1 = 1; a2 = 2; b = PHI(a1,a2)
据说这种表示会给代码优化带来很多方便。据维基百科说很多优化技术的前提是使用SSA。(看了维基百科里一些介绍,懵懵懂懂吧,先留坑,以后再深入)
但是我理解方便的背后,也有一些坑,这个坑就是因为a被“分身”成了a1和a2,后边的函数如果想要引用a的值,到底是用a1还是a2呢?
所以就有个函数叫做PHI,可以确定到底是用a1还是a2,这个PHI念φ,按照我们China NorthEast口音的话应该念fai. 应该是IBM在80年代提出的SSA的论文里用到的符号。
所以φ仅仅是一个理论上的函数定义,能够在静态单赋值情况下解决掉分支选择的问题。
LLVM里的PHI应该是实现了φ功能的API。
所以φ到底是咋实现的呢? 或者说PHI到底是咋实现的呢?
土狗实现就是借助栈,或者寄存器,在a分身的地方把分身放到寄存器里,因为分身是薛定谔的分身,只能在if或者else里,所以赋值一次,再出栈,就实现了。
IR:
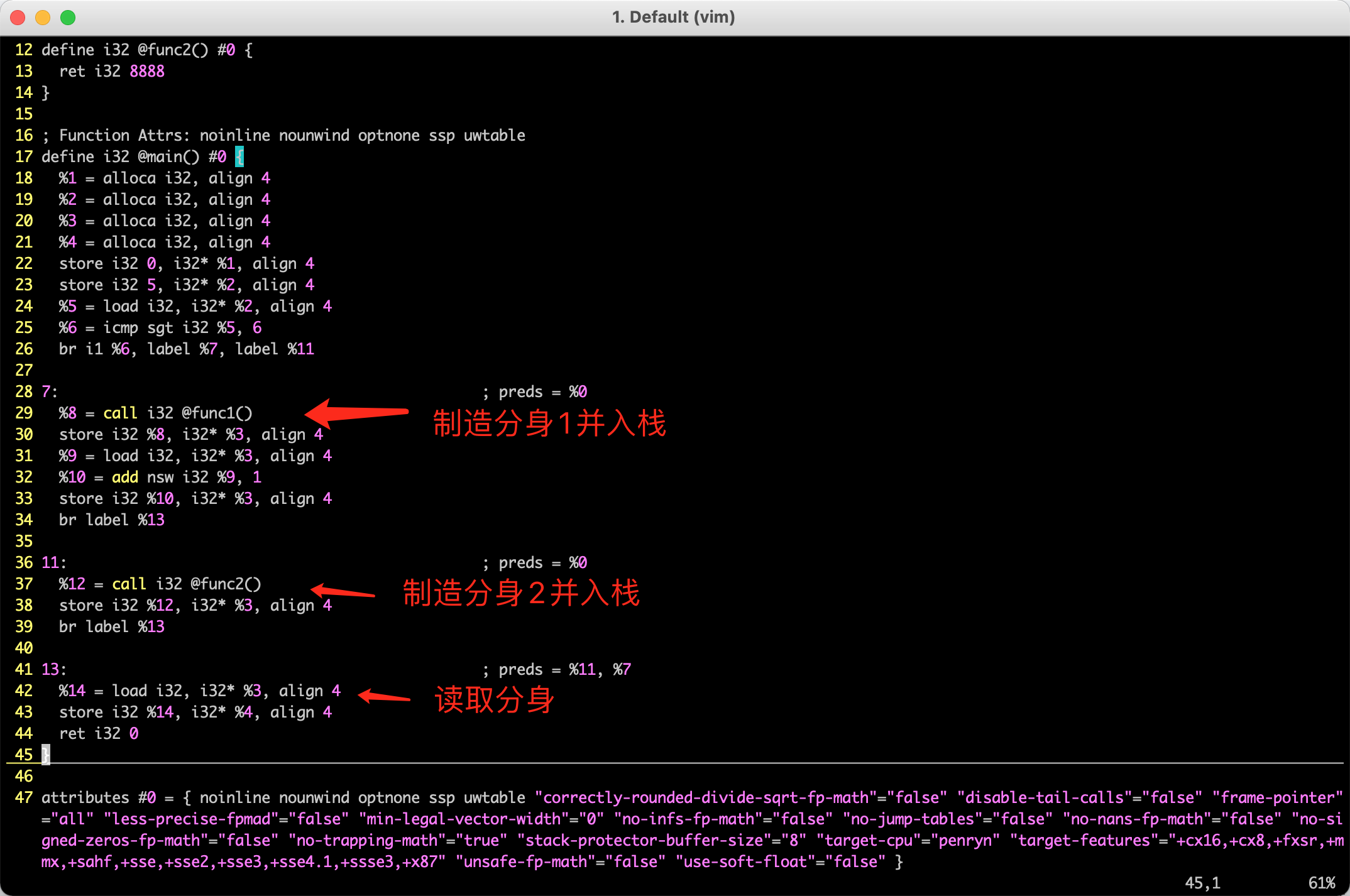
我本来想造一个带PHI 的IR,但是实际编译出来的IR并没有PHI,而是都用store这种方式把PHI给实现了,是我写的if条件太简单了? 还是clang本身就带了实现?
3 个赞
Clang生成的比较简单,想看Phi可以跑PromoteStackToReg
1 个赞
好 谢张总 先记小本本
膜拜一下 紫薯布丁
最近几天没什么大块的时间用来看书,大部分时间开会,在会议期间看了一些文档。记个笔记。
首先看了一下LLVM的API建立个整体概念,主要是Kaleidoscope里的用到的,几个比较重要的类
Moudle->Function->BasicBlock->Instruction
模块由函数组成
函数由基本块组成,
基本块由指令组成,
下级getParent可以拿到父级,上级通过迭代可以遍历下级,基本就是这么个逻辑,整体有个概念混个脸熟先。
IRBuilder类用来构建IR
另外还有两个重要的类,Function和Value,作为codegen方法的返回值
基本看完这些可以去实践一波了。
另外是clang,
超级长的文档https://clang.llvm.org/docs/index.html
我本来想在找一下为什么clang生成的IR里没有phi node,是不是有什么优化配置没关掉。然后clang help了一下,结果这参数真是把我吓了一大跳,十分多,后来我干脆把参数导入到log里。
clang -help >> /tmp/xxx.log && open /tmp/xxx.log
有一些参数比较眼熟,简单记录:
-
-###
Print (but do not run) the commands to run for this compilation
感觉这个参数有点像shell里的假执行 -
-mllvm
Additional arguments to forward to LLVM’s option processing
这个ollvm和张总的光里面都用到了,用来给clang传值 -
-S Only run preprocess and compilation steps
-c Only run preprocess, compile, and assemble steps
这俩写一起了,控制执行哪些处理过程 -
-emit-llvm Use the LLVM representation for assembler and object files
用LLVM IR来表示.o文件 -
-o Write output to
输出到文件,后边接个-的话,直接在终端就能看到
另外还有-Objc -target等,随用随查,或者直接编译XCode工程,看log里有哪些参数。
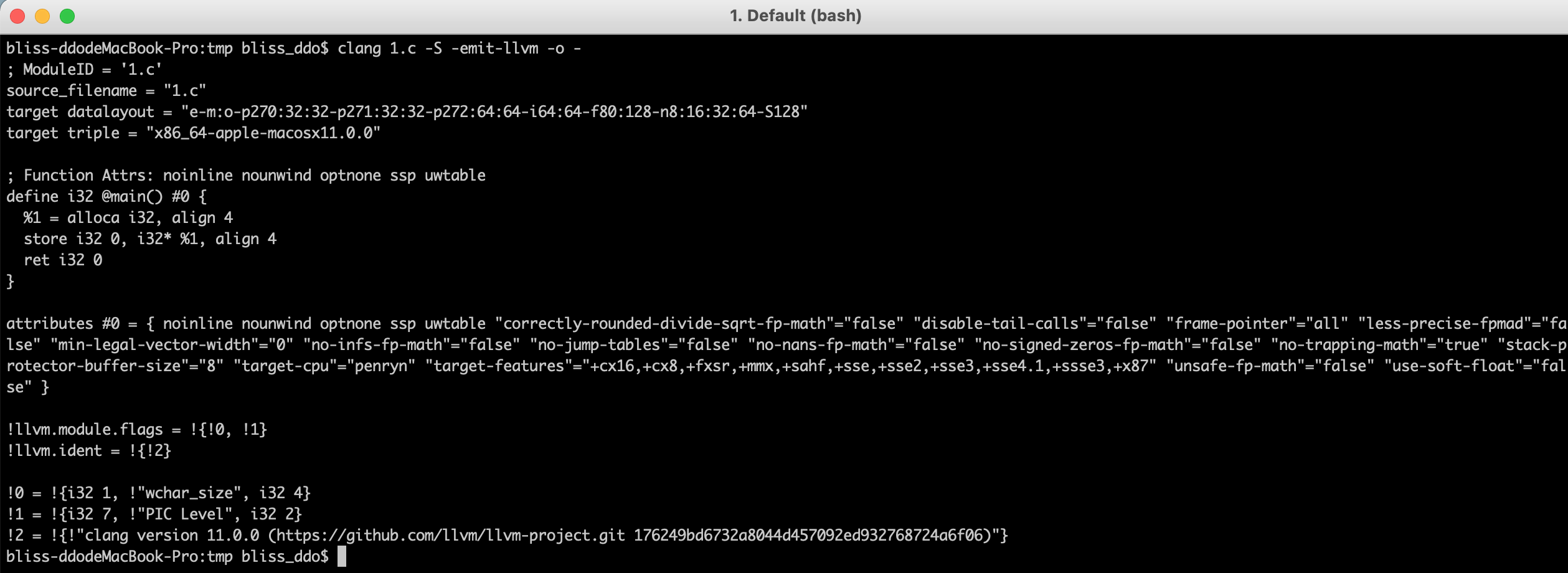
示例,随便搞个test.c
clang 1.c -S -emit-llvm -o -
您好,我也在自己编译 xcode 12 编译的时候出现了很多i386架构不存在的问题,请问您怎么解决的
好长时间没有更新了
最近没法当咸鱼了
催更。。。紫薯布丁
最近公司发生了一些事情,我从一条只需要管好自己并且负责好coding的咸鱼,被动的上位成为了每天开会和写PPT的无用工程师。摸鱼时间基本没了。最近一段时间临近年关,我需要好好规划一下我的时间了,向各位大佬保证,这个帖子我会一直更新,频率慢一些。
暗示成为阿里P9了
1 个赞
张总抬爱了 。目前是个小破公司的Puaee。时刻接受上级Pua。
。目前是个小破公司的Puaee。时刻接受上级Pua。
Kaleidoscope第四章
https://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl04.html
这章的小目标是增加JIT和优化器。JIT就是能Just in time,即时执行,有脚本语言那味了。
这章先提了一下常量折叠(constant folding)的概念.其实就是在编译阶段,把能计算出结果的表达式直接给计算出来,这样可以省下很多指令。比如第三章的 1+2+x 本来是2个加号,也就是两条add指令,通过常量折叠把1+2提前变成3,代码就变成了3+x,只有1个加号,也就是一条add指令就OK了。
many language implementors implement constant folding support in their AST representation.
有些语言把常量折叠这个优化直接给(前置)放到生成AST阶段了。
LLVM的IRBuilder内部自动的实现了常量折叠。
但是IRBuilder也有局限性。比如 (1+2+x)*(x+(1+2)) 这个表达式,生成的IR里
tmp0 = 3+x
tmp1 = x+3
res0 = tmp0 * tmp1
也就是说虽然常量折叠了,x+3和3+x这种满足加法交换律的等价表达式被执行了两次计算,理想状态是能够识别出这种表达式,然后进行优化。所以这块引出了两个优化的概念:
reassociation of expressions 关联表达式
Common Subexpression Elimination (CSE) 公共子表达式消除
这块又会对应到一大波理论。暂时略过。
同时也引出了llvm里的优化上的工程实现,也是最为被开发者津津乐道的,llvm pass。
写点心得:
我感觉做编译器,两个相反的方向,一种是优化,让生成的指令尽可能的少,执行效率尽可能的高。另外一种是做混淆,让指令尽可能的复杂,迷惑破解者。但是不管做哪个方向,都要对代码这些基本的概念有了解。即使不那么理论,也要大概知道API是做什么的,解决什么问题的。
接下来的一节,开始讲pass。
第一段说pass可以组合起来使用,开发者可以自己指定用哪些pass,什么顺序
第二段说的是pass的作用范围,可以是per-function,也就是单独作用在某些函数上面,也可以是whole module ,也就是作用于整个模块,这个模块一般来说是一个文件,当然如果是处于连接阶段,编译器像拼图一样把编译好的obj拼到一起,变成一个巨大的module,那这个时候这个module就不是单个文件了。
然后结合了Kaleidoscopic ,讲了一下具体使用
FunctionPassManager 用来管理pass,
初始化的时候传入的是一个Module对象,
通过add方法可以add相关的pass到manager里,
调用run方法传入之前定义的FunctionAST的codegen方法里传入Function对象。就把pass作用到了函数上。
还有一节内容比较多,我还没太看懂,看懂了在更。
1 个赞
太强了。 这就是P8吗
P(PT)8
催更了,紫薯布丁
膜拜 字数补丁
膜拜 字数补丁
膜拜 字数补丁