一直比较喜欢逆向分析的研究,多年前非常喜欢dynamoRIO(好像没怎么更新了也不支持ios mac平台)专门研究学习了很久,到最近尝试用frida进行研究,不过总是遇到很多问题,被针对性检测都是小问题(比如有的软件你的lib出现frida名字就直接崩溃),主要是兼容性问题和效率问题,frida发挥最大作用的地方应该是越狱状态下的调试,在非越狱状态下有的把frida打包启动就直接崩溃了,可能是依赖项太多,注释掉frida相关功能就好了。我觉得效率问题才是最致命的,在手机上可能并不明显,因为手机app厂商考虑的最核心问题是用户体验问题,而mac上就不同了,我用frida曾尝试逆向跟踪imazing结果发现经常无限卡死(我曾相信frida可以从启动开始同时跟踪所有线程),后来我才发现其中的死结:imazing有的线程启动了2秒后定时重启的功能,如果2秒内frida stalker跟踪没有完成(这经常发生因为imazing的保护强度是非常高的)就再开启一个相同的线程,结果就是无限循环最后崩溃。而且你用frida stalker跟踪你需要先确定你找的东西的位置,这就有点像是先有鸡还是先有蛋的问题。
所以,我就尝试是否可以在非越狱状态下开发一套工具,既能跟踪所有函数(对,是所有线程运行时候尽可能多的函数)的调用轨迹,又能跟踪所有堆内存的读写,这样你就几乎一眼看清楚整个程序的全部逻辑(当前,如果数据量特别巨大就需要分段跟踪)。经过查阅相关的学术文献和多年的经验思考,我使用了一种算是比较新的逆向思路去解决这个问题,设计这个工具。
学术界程序分析有静态二进制重写翻译和动态二进制跟踪两大主要方向,我们通常网上看到的逆向类文章其实主要是动态二进制跟踪为主,因为静态翻译看上去比较麻烦,我简单介绍下二进制静态翻译,就是把程序通过静态分析完成所有插桩,但是因为程序间接跳转地址是未知的所以有很多问题,而且x86指令大小长度不定,所以极大概率会造成指令错误解析、不完全解析,但是mac ios上就几乎没有这个问题,因为arm64指令都是4字节的,而且由于苹果系统越来越严格的要求,几乎完全禁止了软件动态修改自身代码jit,这对于静态分析其实是非常有利的。所以我就结合了静态翻译和动态运行结合的思路设计一种程序跟踪工具。首先,通过结合ida的静态分析结果,把需要的程序片段整个静态插桩,这样就几乎不存在效率的问题,实测下来速度影响不超过50%,而frida stalker的速度影响可能是几十倍的降低。
首先,我在mac上测试imazing跟踪结果,终于可以跟踪imazing所有函数调用和堆内存读写了,因为它的主程序也才几十兆,但是它的保护强度却是非常高的,它的一些核心功能调用之前往往需要几万、几十万次的函数调用(有一次我尝试无聊想直接跳到最后直接被作者嘲弄了,看到了一句:dead face),但是我的工具全都实时跟踪下来了,只是由于没有付费证书,一次完整的流程都没有,我只能跳过它的一些次数限制,而一些付费功能我就放弃研究了。
后来,我在ios系统上跟踪,就遇到了新的问题,ios 主程序异常庞大,用ida分析可能需要几个小时,就不得不分段跟踪,但是对于系统调用,我们可以几乎全量跟踪,因为ios系统的一些核心信息全部可以通过Object C的msgsend函数看到,虽然都说android逆向更容易,其实ios程序这种结构也为逆向分析提供了巨大的帮助。比如我最近选择尝试逆向小红薯的x-mini-sig算法。就发现一些有意思的结果:
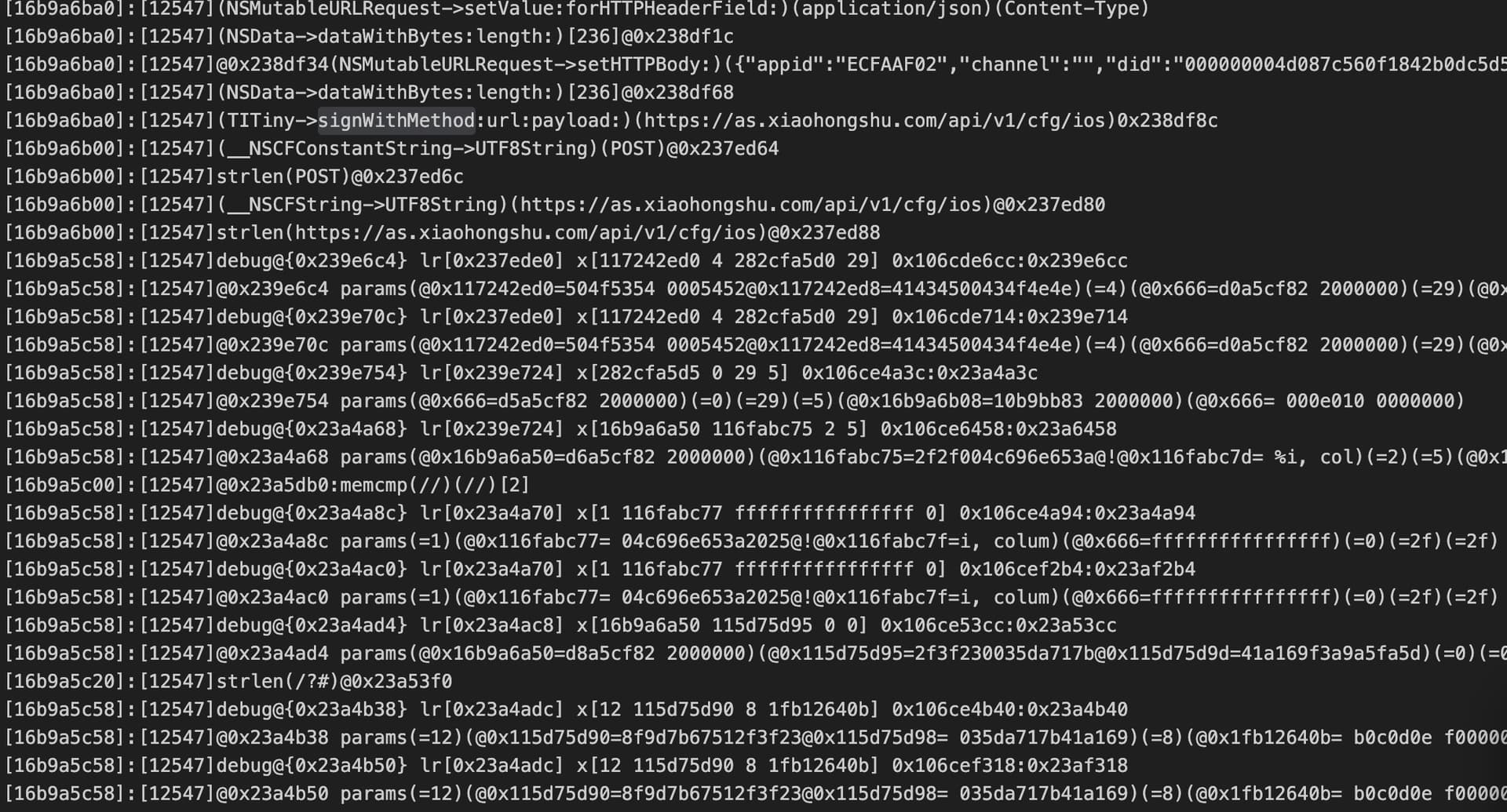
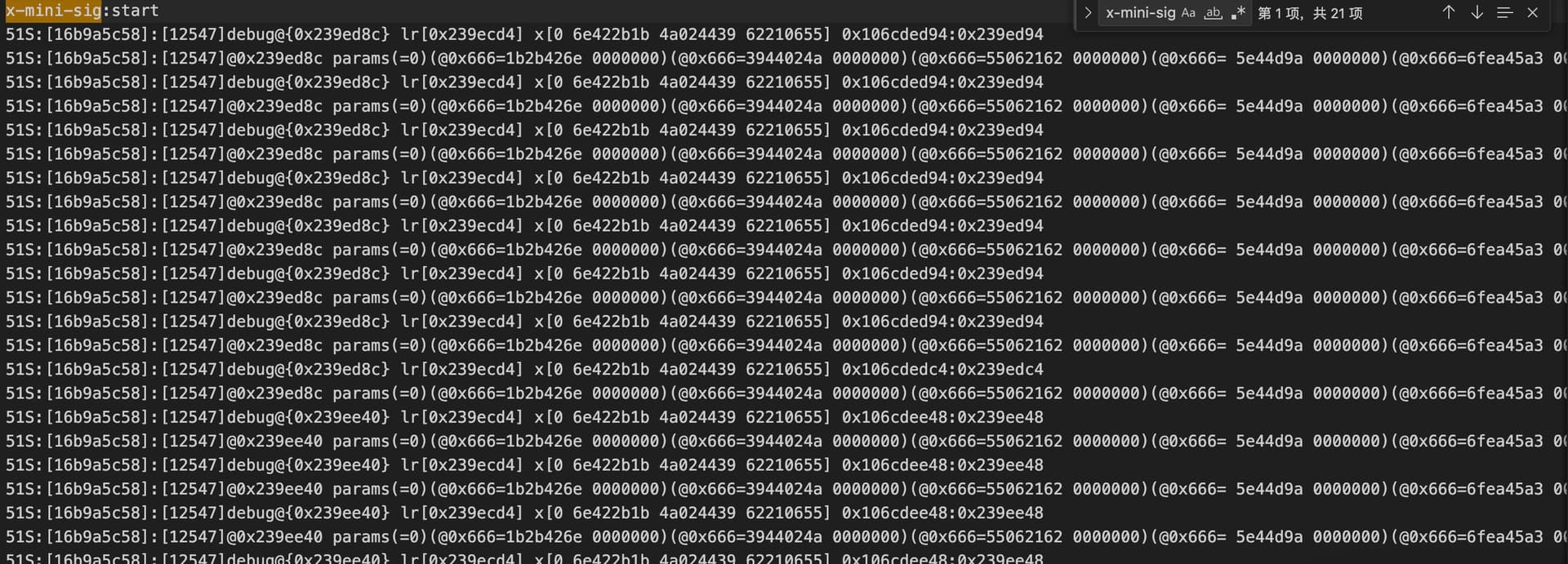
它的输入就是httpbody+body哈希+x-mini-mua参数 最后在进行sha256哈希,前面的几乎都能用ida清晰看到,但是最后他们用了一些自定义的算法可能是混淆控制流虚拟化之类的,但是强度依然不算高,总共跟踪了1000个函数左右,这和imazing上万、几十万函数不能相提并论。关键是,这些混淆函数模式几乎相同,寄存器也是有限的几个,而且堆栈地址(16b9a5c58)不变,说明他们就是专门为这个一个函数开发了一套混淆虚拟化工具,而且代码的集中度非常高,这些函数的跳转地址固定(ida中这些函数跳转地址混乱看上去很恐怖),其中甚至不再有其他系统调用而仅仅是把哈希地址的前半部分给修改了(前面的哈希结果作为输入)。所以最后我用python 100多行代码就完成了整个算法的unicore模拟调用执行,算法耗时0.1S多。
x-mini-s1呢,看上去就是根据一个递增的序号进行了他们自定义的一个没有混淆过的sha256哈希,然后同样用上述流程修改了这个哈希的后半部分。对了,我观察到的,这个值就是有限个固定值,那这样加密的意义是什么?
x-mini-mua呢,由于我对于加密算法不是很熟悉,一些细节我没有深究,但是这个参数的计算函数都是ida可解析的明文函数,输入就是系统的一些环境信息的json zlib压缩(789c开头),经过一个秘钥加密,这个秘钥来自一个随机数,看上去还有一个100多字节固定的初始向量吗?
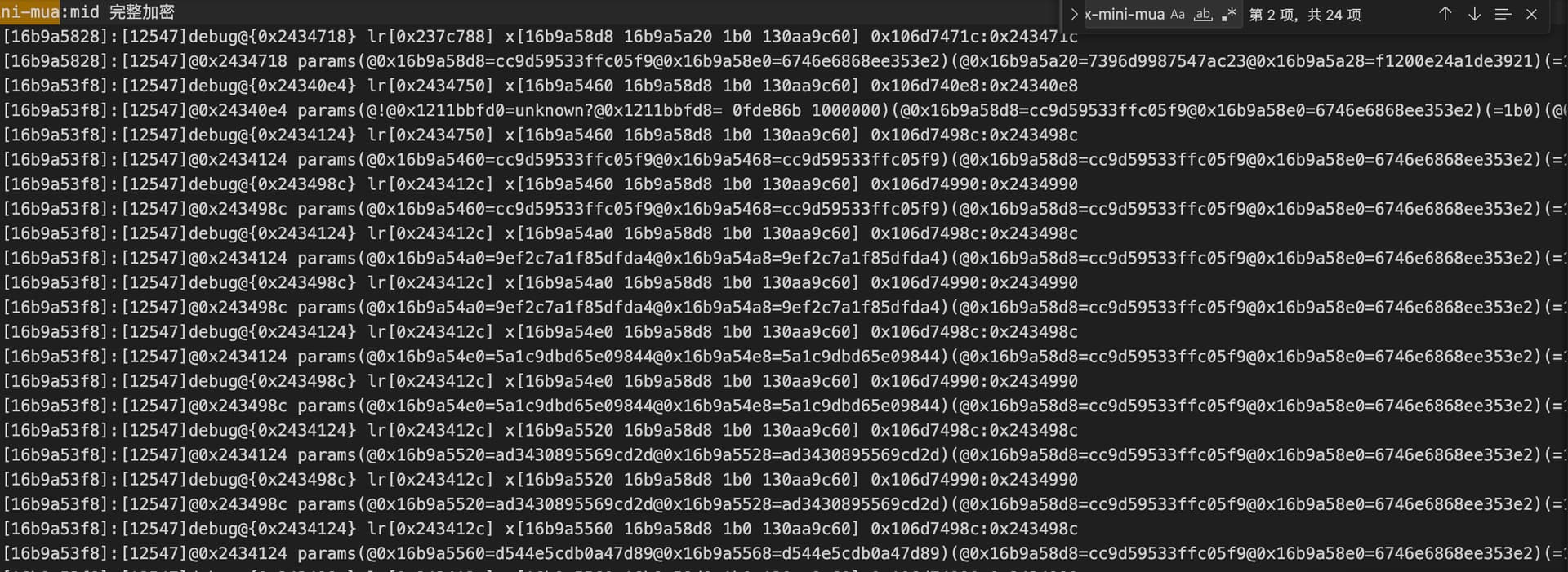
上面这些都是函数调用跟踪和系统调用跟踪(所有线程的,是系统全量跟踪的),下面的是堆内存数据读写跟踪(如果愿意可以跟踪栈内存,因为红薯的混淆算法实际上数据都是在栈上操作的),也是几乎所有线程的。如果要用frida stalker做这种跟踪,速度可能极慢,而且你要先确定跟踪哪个线程,从哪儿开始
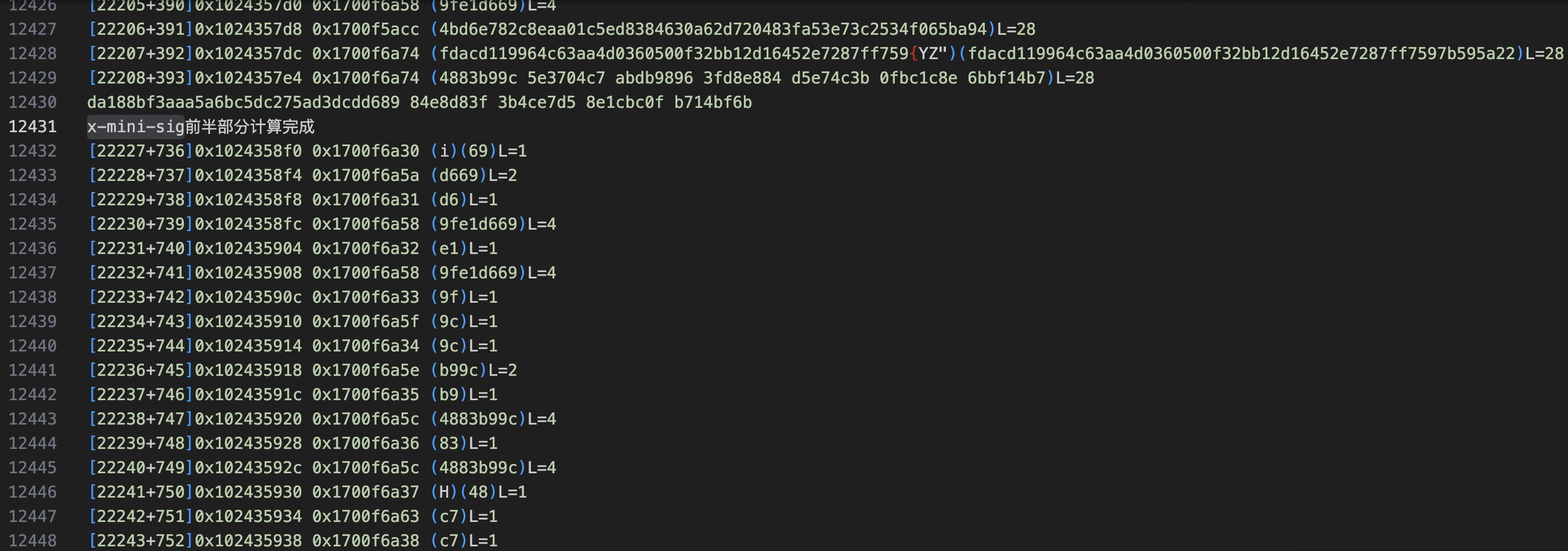
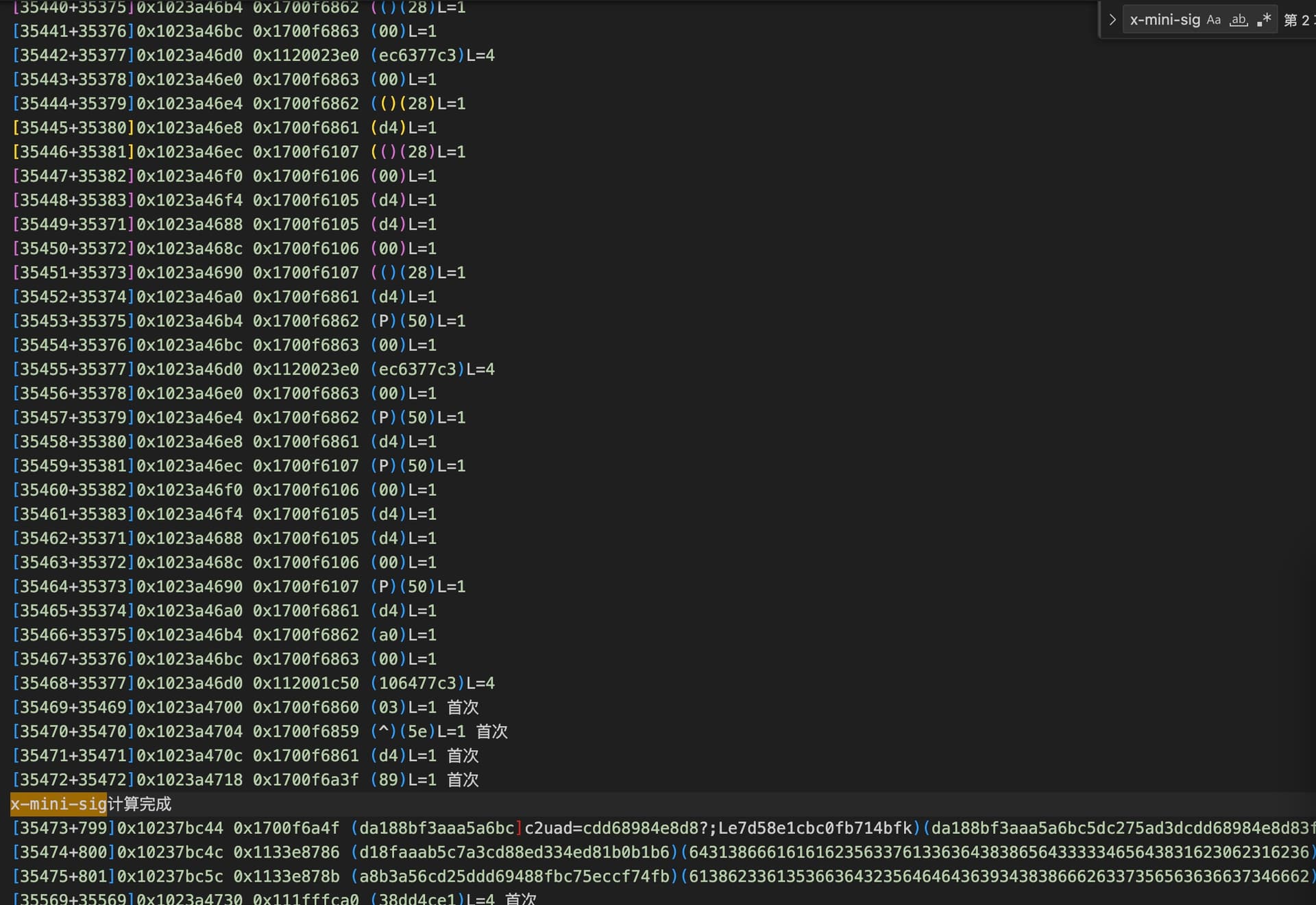
理论上来说,可以做到从某个数据出现,然后逐层往上回溯,发现这个数据最终是哪里来的,但是实践中会有遗漏中断,因为有些数据的转移是通过系统调用memmove memcpy完成的,而且为了效率我没有跟踪所有读写内存的指令,会错过一部分,但是大部分情况下,人工检查就可以基本看清数据来龙去脉。
以上仅供技术研究交流,谢谢!