背景介绍
前言
随着以ChatGPT为代表的文生文大模型“走入寻常百姓家”,许多AI工程师都已经可以熟练调用OpenAI提供的API来开发“套壳”聊天机器人了。
但是,对于更“进阶”的fine-tuning和embeddings来说,很多人还比较陌生。虽然OpenAI提供了官方案例,但在我看来,那只是一个demo中的demo;如果要进一步往生产环节靠拢,还有许多系统工程需要落地。
本文以一个简单的需求起步,通过工程化的分析,串联OpenAI embeddings和Milvus向量数据库,来实现一个可以跑通的demo,最终解决这个需求。
需求
面对浩如烟海的书籍,读者如何找到自己想看的书,一直是一个让人头疼的问题。
例如,新手爸妈想给自己的孩子买本书,打开微信读书,搜索“适合小朋友的书”,看到的是这样的结果:
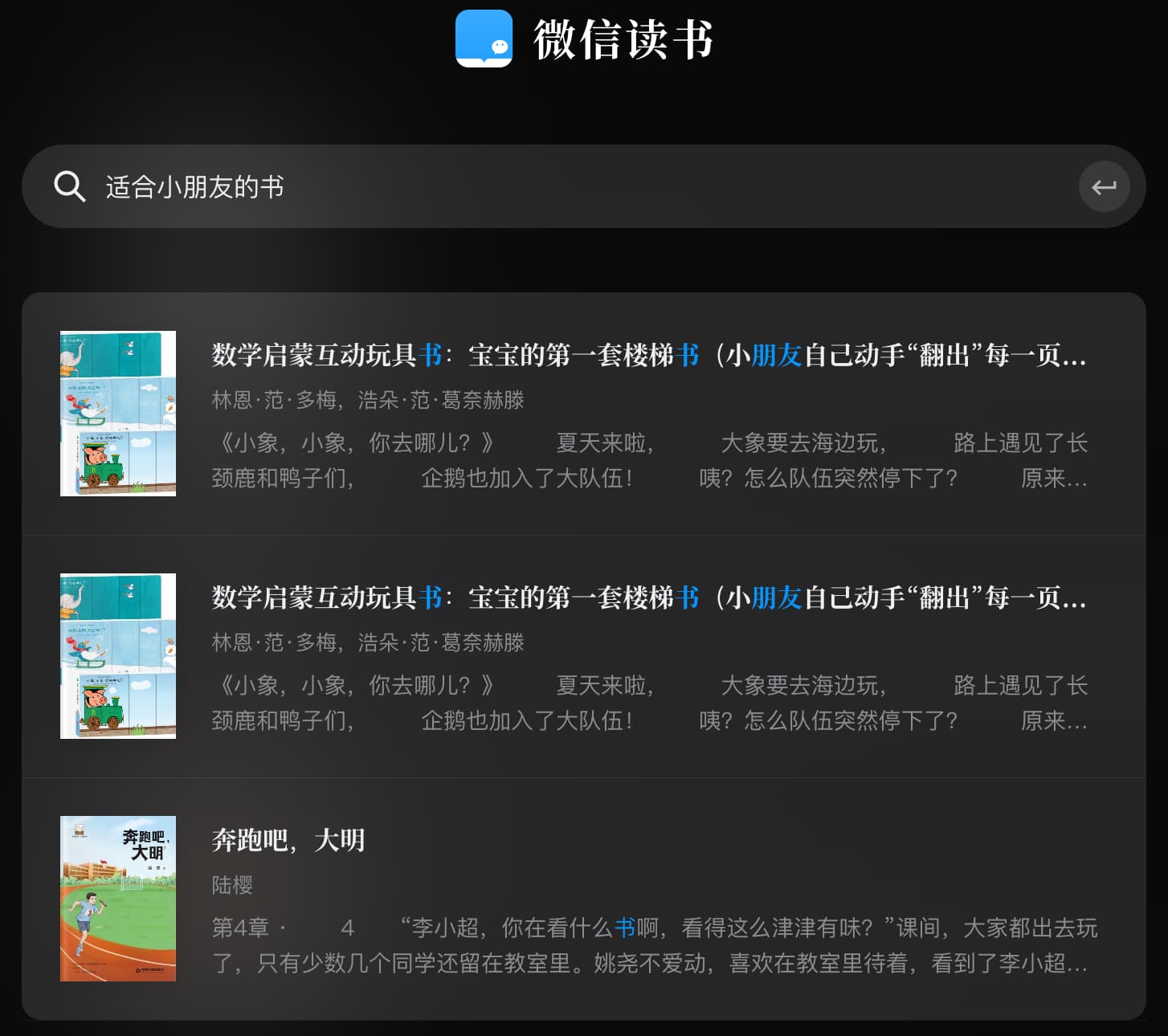
你没看错,只有3本书。为什么?
因为微信读书搜索的方式是“强关联”型,只有匹配到了“朋友”和“书”这两个关键词,才会展示给用户。
如果搜索的是“适合小学生的书”,结果就比较多了:
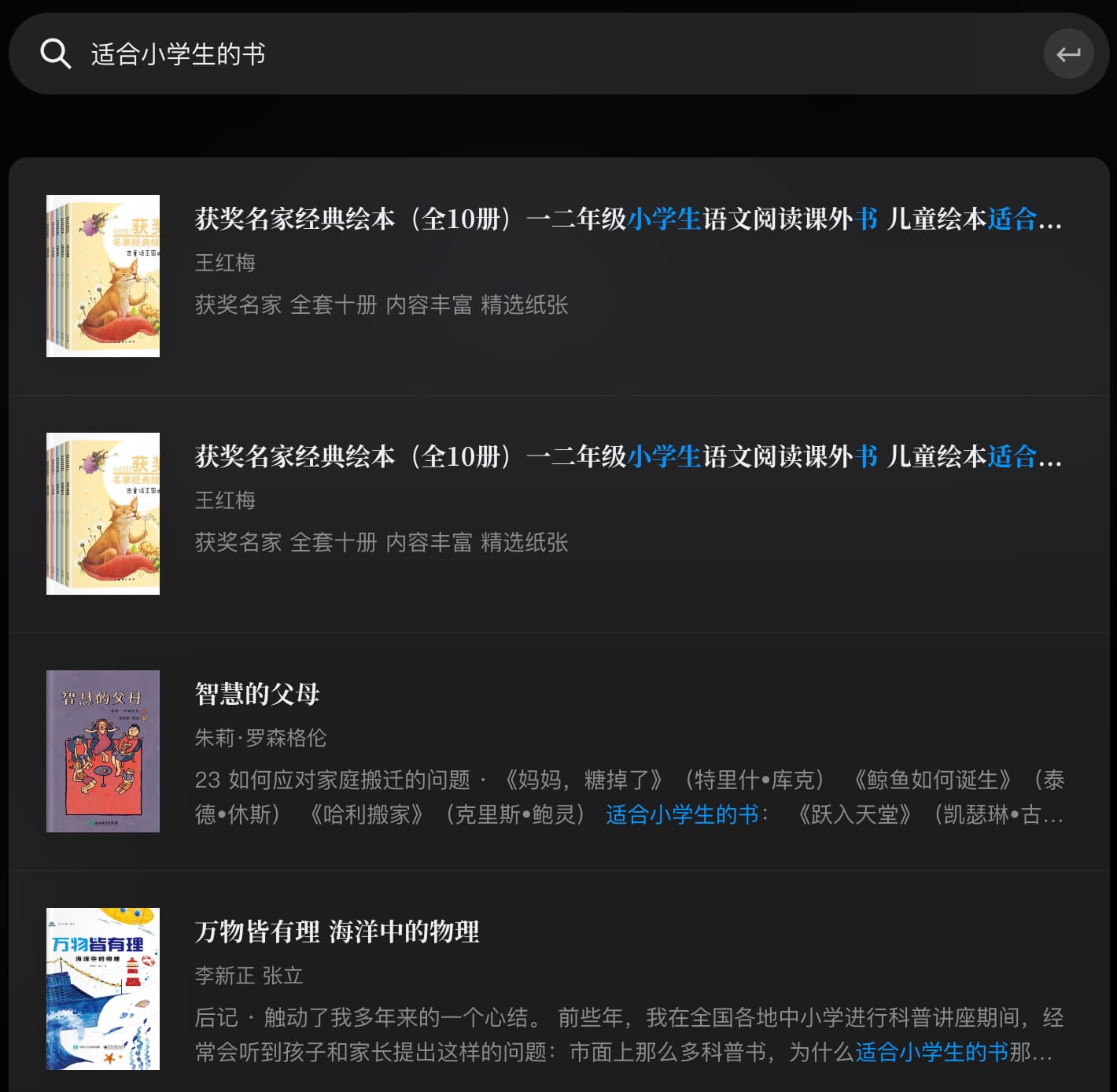
需求毋庸置疑:读者希望在搜“适合小朋友的书”里,也能看到“适合小学生的书”。怎么才能做到呢?用embeddings。
embeddings和向量数据库
什么是embeddings
如果说“强关联”是“非此即彼”,那么embeddings则是“灰色地带”,它们或多或少都“有点关系” —— 它强调的是“相关性”(relatedness)。
什么是相关性?“小朋友”和“小学生”有很大的相关性,“苹果”和“乔布斯”也有一定的相关性。前者可以理解,但后者是为什么呢?因为维度(dimensions)。
“苹果”有很多维度,如果在“水果”这个维度考量,那么它与乔布斯的相关性不算大;而如果在“手机”这个维度考量,那么它与乔布斯的相关性极大。
综合各个维度的相关性,可以得出一个整体相关性;如“苹果”和“乔布斯”的整体相关性必然大于“西瓜”和“乔布斯”。
我们通过把“苹果”、“西瓜”和“乔布斯”这3个关键词分别转换成embeddings,然后比较它们之间的相关性,从而实现“灰色地带”。
把“苹果”转换为embeddings后形如这个样子:
[-0.01668993942439556, 0.0006753962952643633 ... -0.00996478646993637, 0.0036999911535531282]
其中,-0.01668993942439556就是一个维度;OpenAI提供的embeddings模型,即text-embedding-ada-002,有1536个维度。
Embeddings、dimensions和relatedness的专业解释可参考OpenAI官网原文:
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
存储embeddings
OpenAI的示例代码里,embeddings都存放在csv里。作为demo演示没问题,但用于生产环节,数据量大了之后,存在csv里肯定不合适,要用数据库。
数据库
注:数据库的介绍搬运自西南证券-人工智能行业专题研究-向量数据库:AI时代的技术基座。
大家日常提到的数据库,是“以SQL为代表的关系型数据库,依据‘一对一、一对多、多对多’的关系模型创建数据库,并将数据以二维表格的形式储存,各个表之间建立关系,通过这些关联的表格间分类、合并、连接或选取等运算来实现数据的管理。”
常见数据库有MySQL、PostgreSQL等。它的优点是数据安全(磁盘)、数据一致性、二维表结构直观,易理解、使用SQL语句操作非常方便,可用于比较复杂的查询;缺点是读写性能较差、不擅长处理较复杂的关系。
2000年左右,互联网应用兴起,需要支持大规模的并发用户,并保持永远在线。一方面,关系型数据库无法支持如此大规模数据和访问量,升级CPU、内存和硬盘可以提高性能,但呈现明显的收益递减效应。另一方面,数据库在机器间的迁移非常复杂,需要较长的停机时间。
NoSQL因此应运而生,有效补充了SQL的适用范围;NoSQL在Web应用领域提供了高可用性和可扩展性。NoSQL没有固定的表结构、数据之间不存在表与表之间的关系、数据之间可以是独立的、NoSQL可用于分布式系统上。
NoSQL数据类型多样,针对不同的数据类型,出现了不同的NoSQL,如向量数据库。
向量数据库
一句话,向量数据库就是为embeddings而生;而我采用的是OpenAI官方推荐的开源向量数据库Milvus。
什么是Milvus?可以看看官方介绍。
安装Milvus
参考官网,具体来说,要关注Prerequisites、Download the YAML file和Start Milvus这三个步骤。
安装完毕之后,就可以开始工程落地了。
实现更“友好”的微信读书搜索demo
大体流程
- 通过Selenium爬虫,获取微信读书信息,作为原始数据。
- 用OpenAI,将原始数据转化为embeddings,作为向量数据。
- 把向量数据集存入Milvus。
- 把用户搜索的内容转化为embeddings。
- 用Milvus来比较各embeddings的相关性。
- 输出搜索结果。
接下来上代码;我会拆的比“大体流程”要更细一些,方便大家消化。
demo代码(Python)
安装依赖库
import XXX里的XXX都安装一下;不会的话问ChatGPT或者Claude。
爬微信读书,拿到原始数据
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
def scrape_weixin_books():
# 启动
driver = webdriver.Chrome()
# 打开某网页
driver.get("https://weread.qq.com/web/category/all")
# 建立等待策略
driver.implicitly_wait(0.5)
# 为了加载所有图书,一直滚动到页面底部
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 执行 JavaScript 代码滚动到页面底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 等待页面加载
time.sleep(2)
# 获取当前页面的新高度
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
books_csv = []
books = driver.find_elements(By.CSS_SELECTOR, ".wr_bookList_item")
for book in books:
title = book.find_element(By.CSS_SELECTOR, ".wr_bookList_item_title").text
author = book.find_element(By.CSS_SELECTOR, ".wr_bookList_item_author a").text
desc = book.find_element(By.CSS_SELECTOR, ".wr_bookList_item_desc").text
books_csv.append({
"书名": title,
"作者": author,
"简介": desc
})
df = pd.DataFrame(books_csv)
df.to_csv("books.csv", index=False)
driver.quit()
scrape_weixin_books()
拿到了books.csv,你双击打开看看就知道长什么样了。
二次加工,把关键信息整合到一起,为embeddings做准备
import csv
# 读取原始的 books.csv 文件
with open('books.csv', 'r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
rows = [row for row in reader]
# 在每行的末尾添加 fusion 列的值
rows[0].append('fusion')
for row in rows[1:]:
fusion_value = f"书名:`{row[0]}`,作者:`{row[1]}`,简介:`{row[2]}`"
row.append(fusion_value)
# 将结果写入 books_fusion.csv 文件
with open('books_fusion.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(rows)
拿到了books_fusion.csv,你双击打开看看就知道长什么样了。
启动Milvus
- 打开Docker.app(我用的是macOS)。
- Terminal中执行
docker-compose up -d。 - 可以通过
docker-compose ps来判断是否启动。
基础配置
import csv
import openai
from openai.embeddings_utils import get_embedding
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# Milvus配置
FILE = './books_fusion.csv' # 需要生成的embeddings来自books_fusion.csv
COLLECTION_NAME = 'books_db' # 数据库表名
DIMENSION = 1536 # OpenAI的embedding有1536个dimensions(维度)
MILVUS_HOST = 'localhost' # Milvus server URI
MILVUS_PORT = '19530'
index_params = {
'index_type': 'IVF_FLAT', # 有FLAT、IVF_FLAT、IVF_SQ8、IVF_PQ、HNSW、ANNOY和DISKANN
'metric_type': 'L2', # 有L2和IP
'params': {'nlist': 1024}
}
search_params = {
"metric_type": "L2",
'params': {'nlist': 1024}
}
# OpenAI配置
OPENAI_ENGINE = 'text-embedding-ada-002'
openai.api_key = "sk-XXX"
openai.api_base = "XXX" # 如果你不想科学上网,可以参考https://github.com/Ice-Hazymoon/openai-scf-proxy来实现反向代理
定义OpenAI embeddings函数
def embed(text):
# 有好几种方式,我实测后感觉效果差不多,所以用的第一种
return get_embedding(text, engine=OPENAI_ENGINE)
return openai.Embedding.create(input=text, engine=OPENAI_ENGINE)["data"][0]["embedding"]
return [x['embedding'] for x in openai.Embedding.create(input=text, engine=OPENAI_ENGINE)['data']][0]
创建一个新数据库
# 链接到Milvus
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
# 新建一个数据库
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
# 新建数据库里的3个字段
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name='fusion', dtype=DataType.VARCHAR, max_length=64000),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
collection.create_index(field_name="embedding", index_params=index_params)
用OpenAI将books_fusion.csv里的fusion生成embeddings,然后存入数据库
def csv_load(file):
with open(file, 'r') as f:
reader = csv.reader(f)
for row in reader:
fusion = row[3]
yield fusion
for idx, fusion in enumerate(csv_load(FILE)):
ins = [[idx], [fusion], [embed(fusion)]]
collection.insert(ins)
collection.flush()
# 数据库读入内存
collection.load()
定义搜索函数
def search(text):
results = collection.search(
data=[embed(text)], # Embeded search value
anns_field="embedding", # Search across embeddings
param=search_params,
limit=3, # Limit to 3 results per search
output_fields=['fusion'] # Include title field in result
)
result = []
for hit in results[0]:
row = []
row.extend([f"ID = {hit.id}", f"Score = {hit.score}", f"Fusion = {hit.entity.get('fusion')}"])
result.append(row)
return result
搜索,测试
text = "适合小朋友的书"
for result in search(text):
print(result)
输出的内容:
[‘ID = 127’, ‘Score = 0.3257662057876587’, ‘Fusion = 书名:
窗边的小豆豆,作者:黑柳彻子,简介:★影响20世纪的儿童文学杰作,入选九年制义务教育小学语文课本 ★中文简体版已突破1100万册,连续10年名列开卷全国畅销书排行榜,2017年位居少儿类榜单首位 ★孙云晓、曹文轩、梅子涵、伍美珍、张弘等教育专家联袂推荐 ★新华社、《人民日报》、《中国教育报》、中央电视台深度报道;《新京报》、当当网、新浪网年度图书 ★联合国儿童基金会主 席James P.Grant说:再也没有比她更了解孩子的了。 ★新版隆重上市,更温柔纯真,美观大方,适合亲子共读’]
[‘ID = 55’, ‘Score = 0.33707183599472046’, ‘Fusion = 书名:看你一眼就会笑,作者:丘汉林,简介:小鳄鱼盖朵和他可爱的小伙伴们的疗愈故事!200页趣味暖心漫画,或温馨、或可爱、或搞笑、或黑色幽默……集创意脑洞和可爱疗愈于一体,CHOW希望能传递温暖善意、开心快乐给大家。每个人都有自己的黑夜和寒冬,愿善良温暖的小鳄鱼盖朵能陪伴你左右。’]
[‘ID = 12’, ‘Score = 0.3477523922920227’, ‘Fusion = 书名:小王子,作者:安托万·德·圣埃克苏佩里著,简介:3D动画奇幻电影《小王子》中文配音版于2015年10月16日中国上映!这是一本足以让人永葆童心的不朽经典,被全球亿万读者誉为最值得收藏的书。翻开本书,您将看到遥远星球上的小王子,与美丽而骄傲的玫瑰吵架负气出走,在各星球漫游中,小王子遇到了傲慢的国王、酒鬼、惟利是图的商人,死守教条的地理学家,最后来到地球上,试图找到治愈孤独和痛苦的良方。这时,他遇到一只奇怪的狐狸,于是奇妙而令人惊叹的事情发生了…… 《小王子》犹如透亮的镜子,照出了荒唐的成人世界。她在提醒我们,只有爱,才是最高的哲学,才是我们活下去的唯一理由。’]
我故意没有把所有代码揉在一起,而是把最后一个环节留给你;你再整合、润色一下即可,一点也不难。
比微信读书搜索的效果好吧?