
charles 是个乱码,想问下,是哪里出问题了呢?用什么插件或者工具解析,能明文显示吗?有高手可以提点一下吗~
这应该不是乱码,是人家本来就用这种编码格式,像protobuf
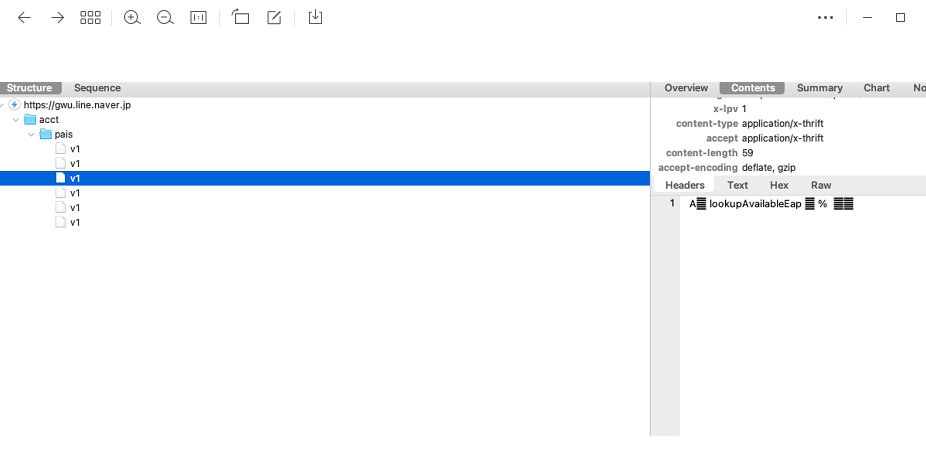
thrift 在 line 中用的是紧凑的二进制格式,类似于 pro,请问有什么办法解析吗?或者经验
如果搜不到现成的工具可用,可以拿解析protobuf的工具改改自己解析,github上有大佬写解析protobuf工具的,找找
你这个不是二进制,看不太清楚, 0x0A 对应的是 1 :
解密数据后,得到如下内容
in:\n 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
16fb94be8 0a 03 61 6c 6c 10 b3 e6 95 f7 8e 80 80 13 ..all.........
::>> protobuffer start
1: "all"
2: 10696053123019571
大概是这样的。
解密算法 比较简单: (前提你弄出二进制字节数组,并且安装protoc)
import subprocess
# reload(sys)
# sys.setdefaultencoding('utf8')
PROTOC_PATH = '/usr/local/bin/protoc'
# 解析当前 data 是否为 proto 的格式
def decode_raw(data):
process = subprocess.Popen([PROTOC_PATH, '--decode_raw'],
stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output = error = None
try:
output, error = process.communicate(data)
except OSError:
pass
finally:
if process.poll() != 0:
process.wait()
return output
bytesArr = b'\x0a\x03all\x10\x80\xa4\xc2\x8c\x86\xd1\xb8\x13'
print(decode_raw(bytesArr))
从0xA来看,基本是protobuff的数据格式了,你把 hex 处理一下
目前大概是 把 0xA 直接转成 hex字符串了,大小没看到二进制不清楚,字符串直接是字符串
确认过眼神,确实是protobuff 的数据的一个变种
这本身就不是 pro,类似但不是
类似pro但不是
你都知道是thrift了,还纠结个啥!