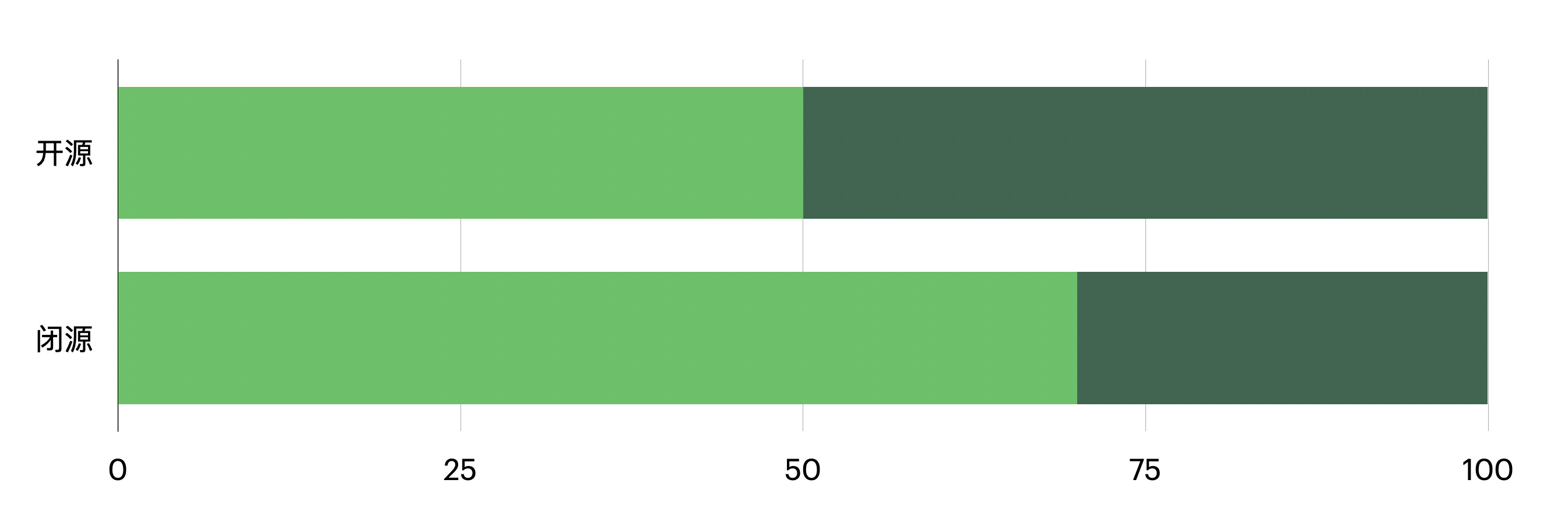本帖用于记录我对不断发展的AI的理解和认知。
注意,我的理解和认知可能是错的;我不是想教你、说服你,而是想留给时间来判断。
同时欢迎讨论、拍砖!
-
为什么要记录?
因为AI发展太快,在我跟进AI的过程中,好记性不如烂笔头。 -
为什么放在这里,而不只是微博、即刻等?
大模型发展的早期阶段,博采众长、大家智慧很重要。为了避免信息茧房,我倾向放在公域上,这样搜索引擎可以爬取到。
本帖用于记录我对不断发展的AI的理解和认知。
注意,我的理解和认知可能是错的;我不是想教你、说服你,而是想留给时间来判断。
同时欢迎讨论、拍砖!
为什么要记录?
因为AI发展太快,在我跟进AI的过程中,好记性不如烂笔头。
为什么放在这里,而不只是微博、即刻等?
大模型发展的早期阶段,博采众长、大家智慧很重要。为了避免信息茧房,我倾向放在公域上,这样搜索引擎可以爬取到。
其实就是一本说明书、教程、文档。它的核心要求很简单,也很难:
看过《iOS应用逆向工程》的朋友,会发现完全符合1、2、3的要求。所以写过说明书、教程、文档的朋友写prompt,会非常得心应手
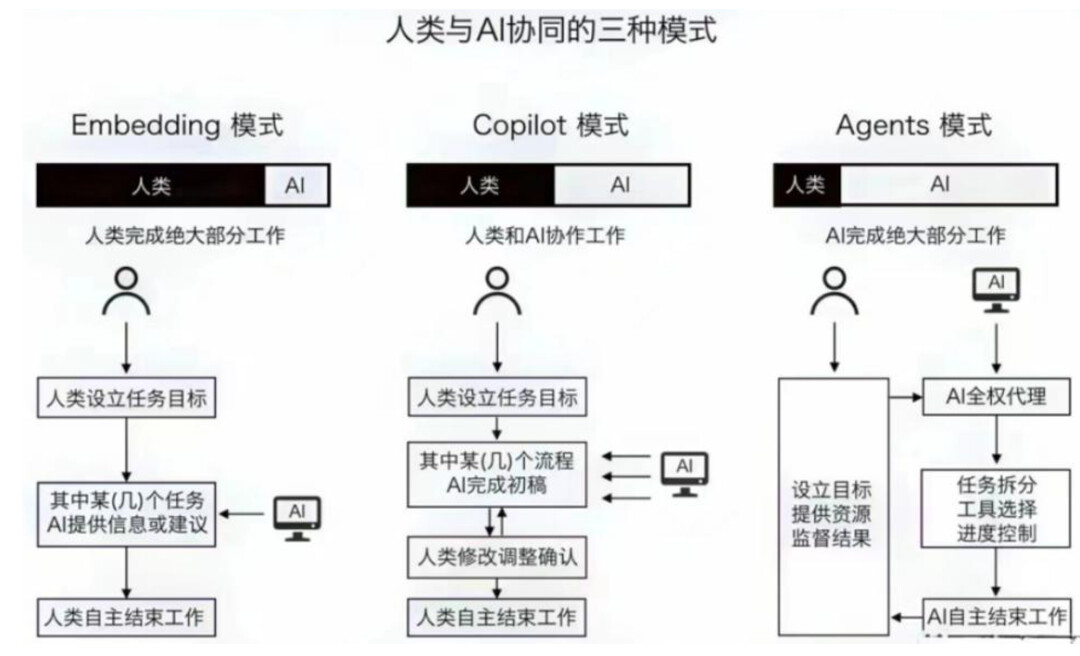
智能体是一个新概念,目前尚未完全达成共识。从我的角度来看,智能体有三大特点。
围绕AI打造产品。AI是大脑,其他由大脑指挥。
传统软件(如小程序/app)的特点是可以穷举。如伪代码:
if ...
else if ...
else if ...
而智能体比传统软件复杂,它无法穷举。如伪prompt:
你是一名心理学家。我给你一段话,你判断它是积极的还是消极的:……
当情况变得复杂,无法穷举时,传统软件解决不了问题,必须堆人力,变得“劳动密集”;为了解决这个问题,智能体应运而生,让“一人公司”、“超级个体”成为可能。
OpenAI定义了文生文的AI范式:以对话(chat)的形式工作,输入prompt,输出completion。
ChatGPT-3.5发布爆火后,所有其他的文生文大模型都遵循了这个范式。
OpenAI是闭源的,它相当于文生文大模型里的iPhone。
与之对应的,文生文大模型里的Android,就是ChatGLM、baichuan、Qwen、Llama等开源大模型
大多数工程师没有研发基础大模型的能力,这个是博士、研究员、科学家才能干的事。
类比起来,基础大模型是操作系统或内核,应用就是软件、网站、app、小程序等。
其实在互联网和移动互联网时代,做操作系统和内核开发也是少数人,大多数人还是在做应用。
到了AI时代,这条路径不会改变,一定还是少部分人做基础大模型,绝大部分人做应用
感谢分享
豆包的产品力提升肉眼可见,真的佩服!
DeepSeek R1跟OpenAI的o1和o3 mini没啥区别了,那自然要支持国产了
2024年两会首提“人工智能+”,看上去很美好,但实际落地时可能很骨感。举个例子:
如果某传统行业没有经历过数字化阶段,那么它要么提供不了足够多的数据,要么提供不了高质量的数据,导致你无法训练/微调AI,只能prompt engineering,而无法使用更高阶的fine-tuning和RAG功能,导致大模型能力有限。
而传统公司因为不懂技术,加上营销号的夸张描述,容易高估AI的能力。有了这个预期落差后,工作就会难一个量级。
前几天看到一个访谈,有句话,值得了解:
不要高估短期内的AI水平,不要低估长期的AI的水平
理想确实丰满 但是3-5年 ai没有盈利 资本就舍弃这玩意了,就像以前的ar vr
chatgpt这种国民级应用都已经出来了,世界级别的事件
延伸上面的话题:
目标是成为阿里P7级别的AI应用专家,能够一杆到底,提供解决方案,。
2023年一整年,我接触过一些有“AI+”需求的传统公司。他们的特点是:
他们的需求是:把看上去高大上的AIGC落地到本行业中,实现降本增效。
如何“把看上去高大上的AIGC落地到本行业中”?其实就一句话:为业务从0到1打通AI工作流。
为了能“为业务从0到1打通AI工作流”,你必须能够成为阿里P7级别的AI应用专家,能够一杆到底,提供解决方案。
业务方是业务专家,对AI一知半解,他不一定分得清产品经理、提示词工程师(prompt engineer)、软件工程师等岗位的区别;他可能会说“就差一个程序员”,而且他没跟你开玩笑。他对你的期望就是“AI+业务”里,“+”的左边你全都可以撑起来。
而“一杆到底”要求你能身兼产品经理、提示词工程师、软件工程师等数职,“一肩挑”;先作为产品经理跟业务方沟通,把他的“一句话需求”扩充成PRD,然后作为提示词工程师实现业务方的需求,最后作为软件工程师将其标准化、工程化,最终提供解决方案。
为了能够一杆到底,在技术层面,你还要对主流文生文大模型、主流文生图大模型、音频、视频、gradio、flask……的日常使用、API调用、部署……都有所涉猎。这个要求……如果不难,人家找你干嘛?
在移动互联网的混沌时期,所有人都在摸索,远没有现在的互联网这么清晰。iPhone出现了,没人会开发app,怎么办?那么会C++的软件工程师,只好吭哧吭哧学Objective-C,成为了初代客户端工程师;不喜欢写代码但头脑比较灵活的图书编辑,天天体验各种app,就变成了初代产品经理;朋友的淘宝店铺里销量持续走高,忙不过来,拉你帮忙,你不小心就成了初代运营……“世上本没有路,走的人多了,也就成了路。”
AI大模型的混沌时期,所有人都在摸索。你很容易就可以入门,成为初代AI产品经理,初代提示词工程师,初代AI软件工程师,也可以成为初代AI产品经理 + 初代提示词工程师 + 初代AI软件工程师,成为一个初代AI应用专家。
混沌时期,想成为初代,门槛真的不高;很多人是把现在的移动互联网高标准给代入到了当下的AI大模型,自己把自己吓跑了。赶紧调整思路,提桶速来!
大佬有什么好的落地方向,现在大家都在做这个赛道,感觉AI作为赋能能做很多有趣的事
现在AI大模型最成熟的就是文生文和文生图,所以好的落地方向就是离文或图最近的方向
用了好几个月,最合适的还是POE。需要科学上网,但还是最合适。推荐!
取决于你能拿到什么数量级别的数据集。
如果数据量小,那么选择闭源大模型API方案。
如果数据量大,那么可以选择开源大模型。
这个比喻不一定恰当;其中浅绿色是大模型的参数量,深绿色是微调的数据集。
也就是说,如果数据量大,那么用开源大模型来微调,有可能达到用小数据集在闭源大模型上微调的效果,同时成本更低。何乐而不为?
《关于AI发展的一点设想》
我们说AI降本增效,其实并非如此,如果只是降本增效,少招/多招几个人就行。
AI的更大作用,在于提高上限。以前需要1年才能做完的事情,未来可能1个月就行,那会很有竞争力。以前品质把控只能做到一般般,未来能稳定产出。
如果借做一款大型游戏只需要1个月,那么就能更快的验证它的市场反应,及时调整,及时反馈和推演。
这个就是降本增效吧?
1年变1个月,就是降本
普通变优秀,就是增效
这个场景是,你已经拿到了文生文大模型公司提供的API(我的情况是公司提供Azure OpenAI API),想找一个电脑上开源、好用的“套壳”UI来调用API。
我先后调研、测试过LobeChat和Chatbot UI,两者都是网页,但前者有点重、有点卡,而且经常报错;后者不支持最新的模型(如GPT-4o),所以都弃用了。目前使用的是Jan,不是网页而是原生app,支持macOS、Windows和Linux,体验不错,推荐!