先把牛逼吹出来,给自己立个flag。 
6 个赞
有哪些资料可以学习的
1 个赞
理论部分直接看编译原理,
实践部分先熟悉熟悉工具cmake ninja 编译出个库 然后照着kaleidoscope往下走,我现在把编译搞定了 把开发环境xcode版本的搭建好了 正在看kaleidoscope
太强了 字数补丁
2 个赞
如果能分享一些学习心得更好了,方便我等小白减少坑
1 个赞
夜深人静老婆孩子都睡着了。中年卢瑟老屌丝来写点LLVM的学习笔记,一方面帮助自己加深记忆,另一方面和大家共同学习。二话不说,直接开始搞。
先编译LLVM:
LLVM有预编译包,可以下载下来直接用。不过我还是自己编译了一份。
LLVM有github,不过github的文档也是从官网上摘抄了一段,还是直接看官网文档比较好(貌似官网文档有些也out of date了,比如编译过程中用到GNU的gcc那一套现在会直接提示不维护,让改换clang)。
我这里用的编译环境是XCode12 + LLVM11.0,直接用最新的。
编译用到CMAKE,下载个App然后按照App提示配置一下环境变量,这部分是基本操作不写了。
先clone代码
git clone https://github.com/llvm/llvm-project.git
然后按照文档:
cd llvm-project
创建一个用来编译的文件夹,我这里用xcode编译,虽然文档上写
Most llvm developers use Ninja.
但是我在对比了几款开发环境(vim,sublime,vscode)之后,还是觉得xcode更好用一些.我自己总结几点原因(个人喜好勿喷):
1 代码自动提示(虽然另外几个也有,但是xcode用的习惯)
2 用lldb方便(llvm demo大多是命令行编译出来的a.out 调试不太方便)
3 算是缺点,就是demo都是命令行。这部分需要有一定基础,能够把命令行里的参数配置到对应xcode的工程配置中,不过llvm的支持xcode项目,所以这部分也不是什么问题。
接着上边,创建用来编译的文件夹:
mkdir my-xcode-build
然后开始生成一个用来编译的工程:
cmake -G <generator> [options] ../llvm
-
尖括号里是必选项目,也就是选择一个generator,也就是你要生成哪种项目模板,这里用xcode
-
方括号里是可选项目,文档有具体解释,有一些比较重要的,比如是否生成动态库,配置编译生成.a的cpu架构,配置是否带断言,这些是支线剧情,为了不对我们的编译产生干扰,这里不配置,也就是使用默认配置。
所以最后命令长这样
cmake -G xcode ../llvm
接下来应该是一番检查,然后生成了一个 LLVM.xcodeproj
打开LLVM.xcodeproj,选择target->buildall,然后等一个小时。
最后都编译通过了,生成了熟悉的老几样lib/bin/include:
-
lib目录,存放用来开发的llvm静态库
-
bin目录,二进制可执行文件,命令行用的
-
include目录,头文件
接下来配置一下环境变量:
vim ~/.bash_profile
添加如下两行:
export LLVM_HOME=/你/自/己/刚/才/的/编/译/路/径/bin
export PATH=$LLVM_HOME:$PATH
wq退出,重启终端或者source ~/.bash_profile
然后随便用一个二进制文件,比如llvm-config,证明配置OK了。
接下来有几个tips:
第一,生成的xcode工程有太多的scheme,为了不让这些scheme干扰视线,先把他们都给隐藏掉,
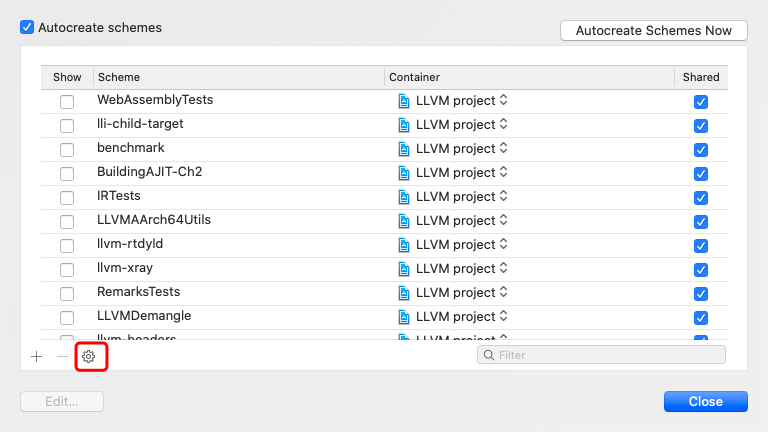
统统隐藏,选一些有用的留下,比如刚才提到的build_all,以及接下来要进行学习的kaleidoscope。
我现在看到demo的第三章,我目前的学习策略是每章先看整体,然后自己duplicate一个target,创建一个相同的文件,从头敲一遍。一来是熟悉代码,避免提笔忘字,二来是自己把最后编译搞定,这个过程我认为是比较重要的。
其实这个时候就可以把玩一下kaleidoscope了,编译一下demo:
今天就先这样了。明天再写。
发帖鞭策自己,争取不烂尾。
5 个赞
-DLLVM_ENABLE_IDE=YES 请
不过我个人觉得IDE用处不大,Debug版的LLVM符号太多了每次LLDB跑起来解析符号就要等很久很久以至于Log调试大法效率远高于上调试器
学习了 已经记到小本本上
嗯嗯 log大法好,我也用过,因为我刚接触llvm开发,kaleidoscope里有些递归的parser,感觉ide断点看起来更直观一些
没太深入搞过前端,感觉实际没有太大的业务场景。我需要用到DSL的时候一般都是可以基于C语言的Clang AST的需求
个人是感觉IRGen开始的整个流程比较有实际价值
3 个赞
主要想补补编译原理的课,也不打算搞那么深入,感觉前段都是一些符号推导,太理论了。前段这款我打算看看基本概念,接着kaleidoscope理顺一下。
继续写笔记,前三章是上周看的,程序调通了,先把笔记记了,做个小结。
http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl01.html
http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl02.html
第一章主要是一些介绍,没什么代码,第二章主要完成了初步的语法分析和词法分析。
第一章制定了一个小目标,实现一个叫做kaleidoscope的语言,这个语言可以用来计算斐波那契数列。所以语言的feture还是挺多的:
- 支持函数定义和调用
- 交互解释,实时求值
- 支持流程控制,if/then/else for循环
- 支持递归
- 可以引用外部extern函数,比如标准库里的cos
- 。。。
看起来还是挺6的。
所以显示词法分析和语法分析,虽然说一般讲原理的树上,把这两块算作两个单独的功能,但是实际coding这两个过程并不是独立的,侧重点不一样
词法分析,主要是扫描生成token,重点在于Scan 也就是读字符,把字符切token
语法分析,主要是解析,生成语法树 重点在于Parse,也就是理解语义,抽象存储
其实我觉得如果想练习词法分析可以去刷刷leetcode,刷一些字符串处理的题目。当然也可以尝试去做点玩具,比如我之前用oc做过一个辣鸡json解析器,这样可以比较好的理解token是啥:
现在看这份代码,感觉就像一坨屎一样 
我觉得token解析,比较重要的一点就是不同的字符,在不同语境下的含义是不一样的,比如同样一个 ‘{’
如果出现在冒号’:’ 之后 ,那么他代表的是一个JSON Object的开始,如果出现在 " 之后,那代表的是字符串的一部分,这让我想起一个段子,用【天真】造句:
1 你很天真
2 今天真热
反正就是大概这个意思。Kaleidoscope里没有这个问题,因为没有字符串,并且参数都是double类型。
前两章主要是定义和描述,逻辑不多,
受限定义token:
然后定义语法树的Node
语法树里定义了一些基本的Node:
- 表达式基类 ExprAST
- 数字表达式 NumberExprAST 用来存数字,成员变量double
- 变量表达式 VariableExprAST 用来存变量,成员变量string,变量名
- 二元表达式 BinaryExprAST 用来存储二元表达式,三个成员变量,二元操作符,左操作数和右操作数,左右操作数是ExprAST类型,递归结构,其实这里就有点递归下降的意思了。
- 函数调用表达式CallExprAST,A调用B,A叫Caller,B叫Callee,成员变量 Callee和参数ArgList
- 函数原型表达式 PrototypeAST,成员变量函数名和参数列表,原型指的是只有声明而没有定义的函数,比如外部模块定义的 extern,成员变量函数名和变量列表
- 函数表达式 FunctionAST ,指的是带实现body(也叫函数体)的函数,成员变量PrototypeAST和函数的Body
最后在来个驱动确定程序的基本框架,也就是while true + getchar 不停地读,读到对应的token,调用对应的handle,然后做对应的parse,parse的过程是递归的,其中还有不同的readToken,handle,parse,这样这个程序就运转起来了。
其实这个部分有一些理论需要学习,比如每个parser开头的注释:
toplevelexpr ::= expression
这个部分应该是文法描述(不是这个词是否准确),对应的术语应该是编译原理书里的生成式,就是箭头那一套
这句定义了toplevelexpr表达式的生成式,
toplevelexpr->expression 也就是toplevelexpr这个文法,可以由expression来生成,所以这里就隐含了程序里的另外一层意思,toplevelexpr的parser实现里一定会调用到expression的parser。
/// expression::= primary binoprhs
expression可以由 primary(翻译成主表达式或者基本表达式?) 和binoprhs二元操作符生成。也就是说expression的parser里一定有调用 primary的parser。所以这样层层嵌套,递归下降。
递归两个要素:
1自己调用自己
2有终结条件
所以表达解析的终结条件就是读到终结符(terminator),编译原理上有一些归纳总结,太理论了,真心啃不动。这里就结合着demo理解个大概吧。。。
中午吃饭了,先写这些,提交,下午接着写。
1 个赞
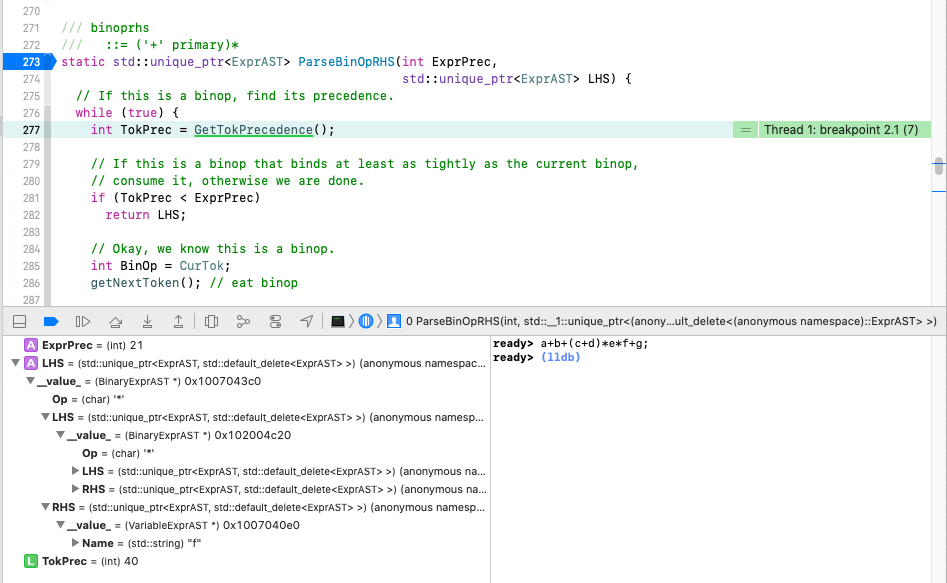
第二章的parser部分比较有意思的是二元表达式的解析,这部分其实编译原理书里也有介绍,具体理论看书,我在这写一下我的理解:
二元表达式主要有个问题就是结合性的问题,一般习惯上我们都按照左结合,貌似树立还讲到了一些其他问题,比如左递归,就是1-2+3 这个表达式,如果按照一般的操作左结合,那结果就是2,但是如果发生左递归,2+3先等于5了,最终表达式变成了1-5也就是-4,这就坑了,所以这是一个问题。
另外的问题就是+和*这种不同优先级操作符的问题。Demo里把这两个问题都解决掉了。而且解决的还挺优雅。代码比较短,但是递归结构设计的挺好,值得学习一下。
核心思想总结一下:
1 递归终止条件,右操作数为空,
2 递归向下传递的是左操作数和运算符优先级
3 每次递归返回的是一个解析好的表达式
有点讲不清楚,直接断点看代码吧,注意一下+号到乘号*的过程
Demo文档中代码编译:
Compile
clang++ -g -O3 toy.cpp llvm-config --cxxflags`
因为我用Xcode,所以在Xcode里找一下对应配置就OK了,生成xcode工程的时候是有example的scheme生成的,简单说明一下:
输入时toy.cpp 对应xcode的build Phase中的compile source
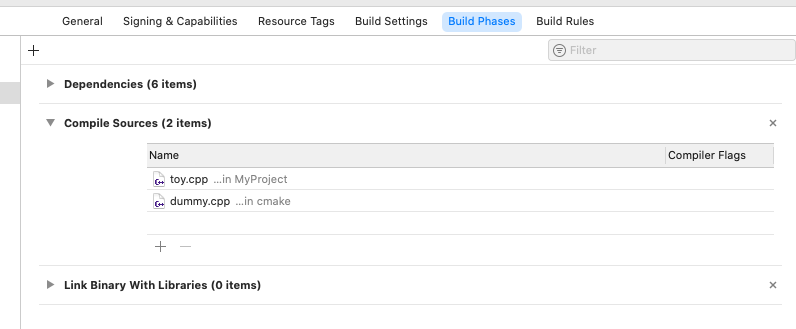
反引号llvm-config -cxxflags 是shell的内联写法,其实就是确定一下编译的参数,对应的xcode build setting中的other c++ flags
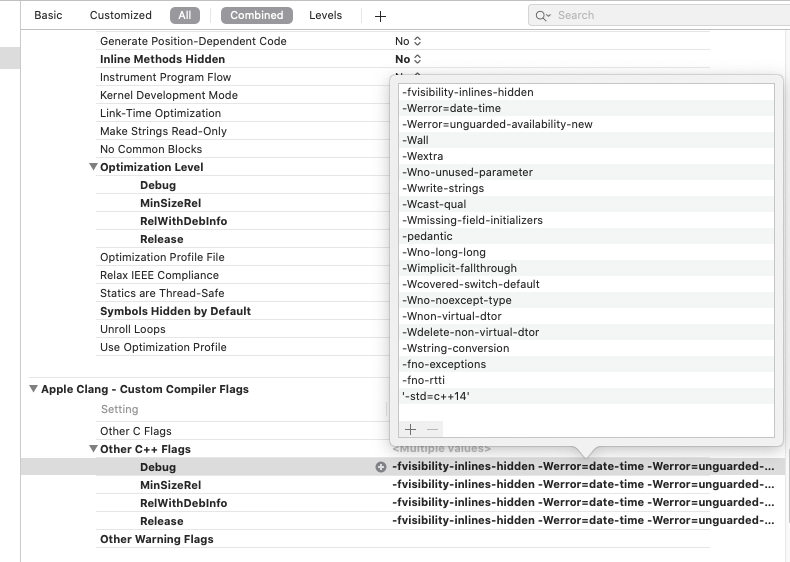
-O3是优化级别
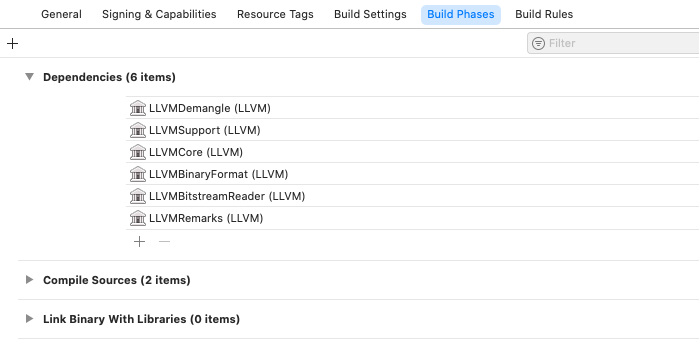
截止目前还没用到LLVM框架中的内容,以后用到配置到Build Phase中的Depency中就可以了
2 个赞
今天看了看 http://llvm.org/docs/LangRef.html#t-struct
主要看懂IR里各种奇怪的符号,以至于后续用API去操作定义这些属性。
比如@开头的是全局变量,%开头的是局部变量,还有一大堆修饰符。
1 个赞
大佬牛皮,v587.
油管上,一个大佬的教程操作的6666,一波入魂
油管上,一个大佬的教程操作的6666,一波入魂
意思是油管上有相关的视频教程?
最近蓝灯,变黑灯了
好像是这个 https://www.youtube.com/channel/UCO4qrmuvmG-fwjsQCYlOyKQ
没法上,不能验证,是不是这个了
能快速 了解 llvm 的前尘往事,还有 初步操作。感觉是个快速入门神器,然后配合源码撸撸,好定方向
太基础了吧这也