之前是因为这贴 http://bbs.iosre.com/t/llvm-pass/9253/65 下的关于符号混淆的讨论以及Hikari开源之后诸多"为什么Hikari不混淆ObjC名称"的问题,一直想写篇相关的东西,今天空了随手糊点字。
Objective-C的方法/类名
其实很简单,因为OC本身语言特性的问题不可能在不限制语言特性的情况下完美无缺。考虑如下代码
@interface AAA:NSObject
-(void)BBB;
@end
@interface CCC:AAA
-(void)BBB;
@end
@implementation DDD
-(void)FFF:(id)arg1{
[arg1 BBB];
}
@end
假设AAA是系统类,也就说编译器不能修改里面的定义。很显然在混淆FFF:的时候混淆工具无法确定这里的SELBBB是应该修改成CCC里BBB混淆后的的名字还是维持不动。 这个问题实际上有很多种变种,但其他所有变种都跟这个例子某种意义上类似。 比如说常见的通过respondToSelector:来运行时判断类型对分析带来的干扰等等。在这个基础上还有分析时跨界的引用问题,比如上例的AAA CCC DDD都在多个翻译单元(aka源代码文件),又或者是子类复写的父类的SEL等等带来的问题,或者更明确一点,都来自语言本身高度的反射机制和最重要的: 类和SEL的解耦合以及泛型/弱类型。 语言本身的设计问题,无法完美解决。 更不要说这些SEL和类型信息走入LLVM IR之后就无法直接获取到了。类名相对会好做一些,但是SEL是一个巨大的坑。
看到这里读者很可能会问: 那么为什么不做一个黑名单机制,即所有系统的SEL/Class都不混淆呢? 这又回归到了设计哲学上的问题。首先不完全统计iOS11为例系统大约有数万个系统类和十万左右的系统SEL,这对于编译过程中的分析是一个无比巨大的内存和性能开销。除此之外还需要额外维护整张表来处理第三方框架等问题。这个过程是非常非常容易出错的。这就回到开头的另一个原因,懒。
传统的C/C++/Swift符号
我私下里用这玩意儿好几年了,反正也不玩这块了随手写点东西发了。轻拍
传统意义上的符号在MachO的__LINKEDIT段里。我们随意编译一份二进制来做demo。
样本 (8.3 KB)
为了方便,我们首先使用MachOView 来观察这个二进制。将二进制拉到MachOView在Docker里的Logo上:
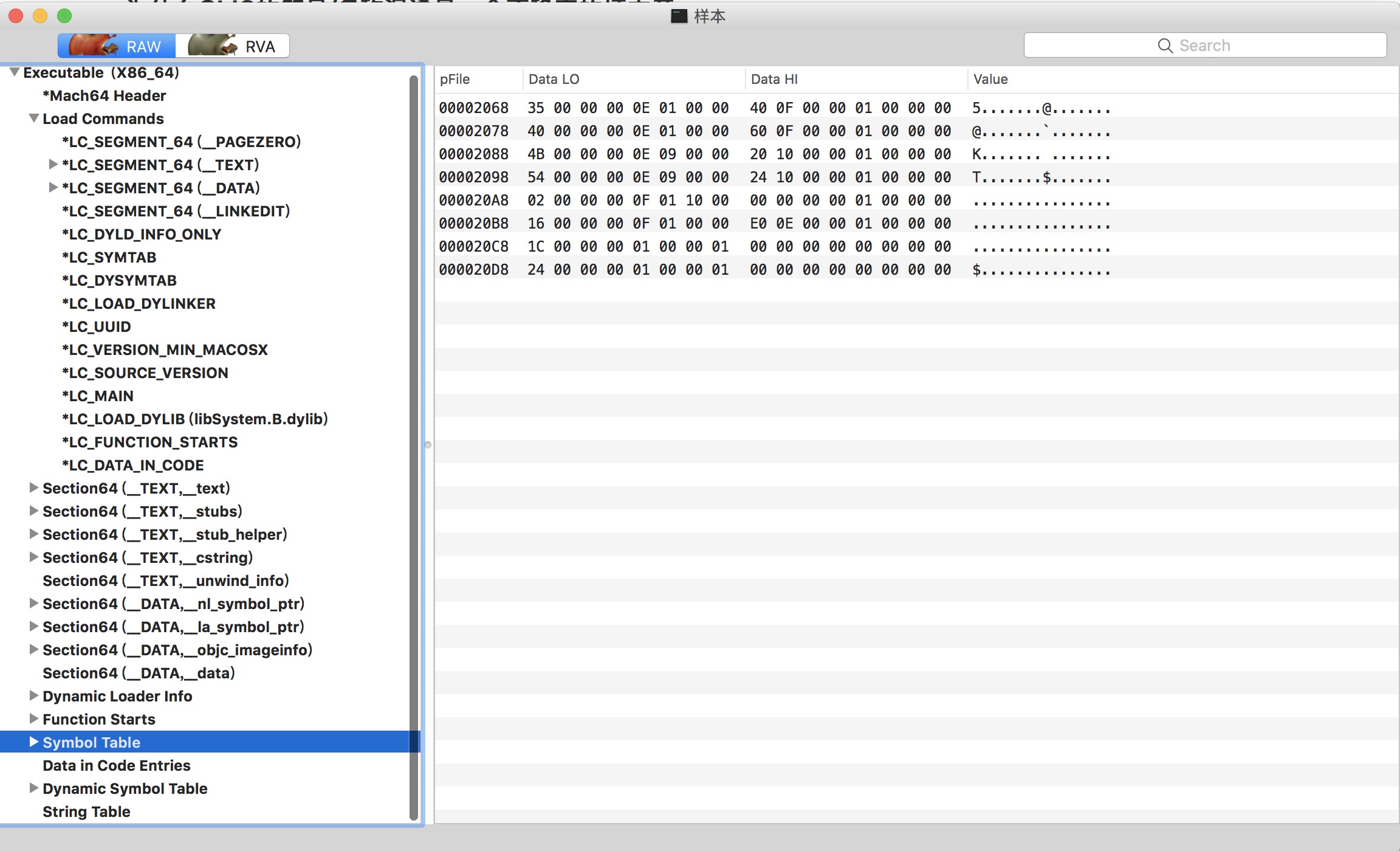
细心的读者已经看到了。下方已经标记好了两个符号表的位置。这两个符号表的地址实质上是由MachO头部的Load Commands中的
LC_SYMTAB和LC_DYSYMTAB决定的。我们观察一下,这里以LC_SYMTAB为例: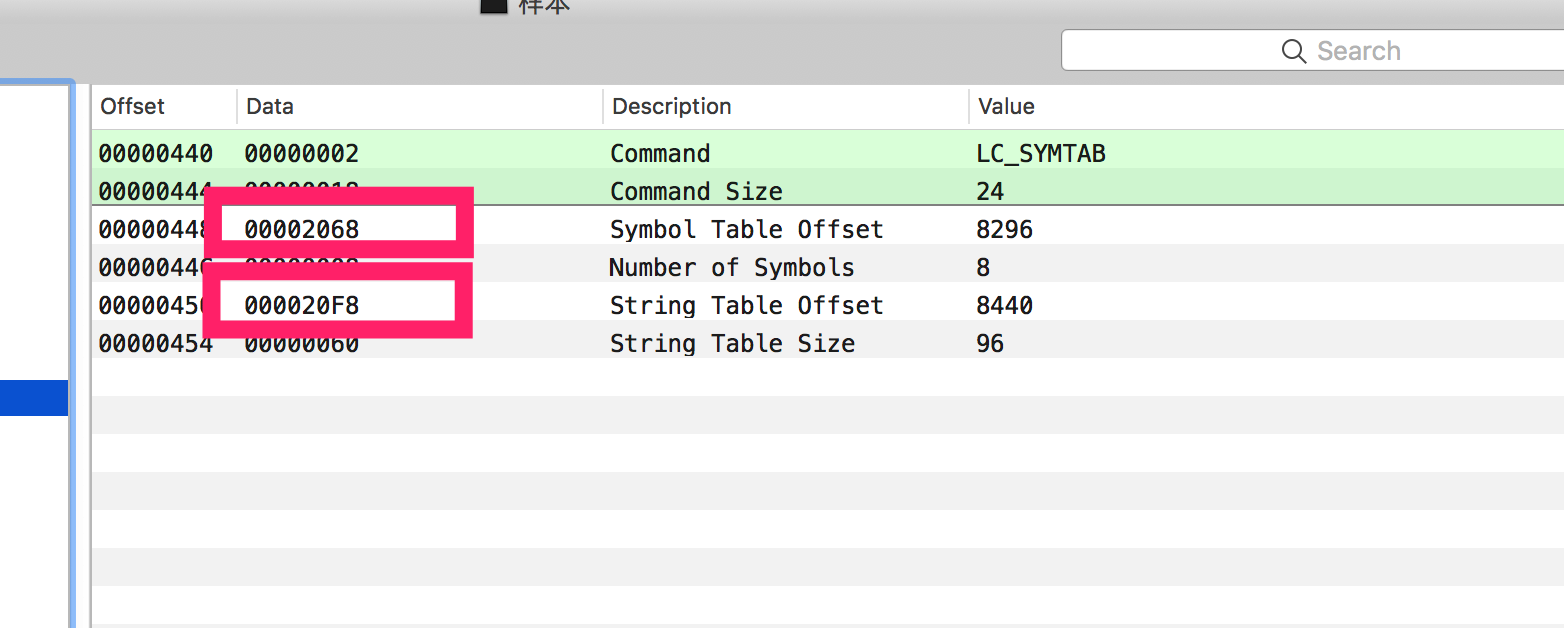
这里的Symbol Table Offset的值是十六进制的0x2068。
看下下面的符号表:
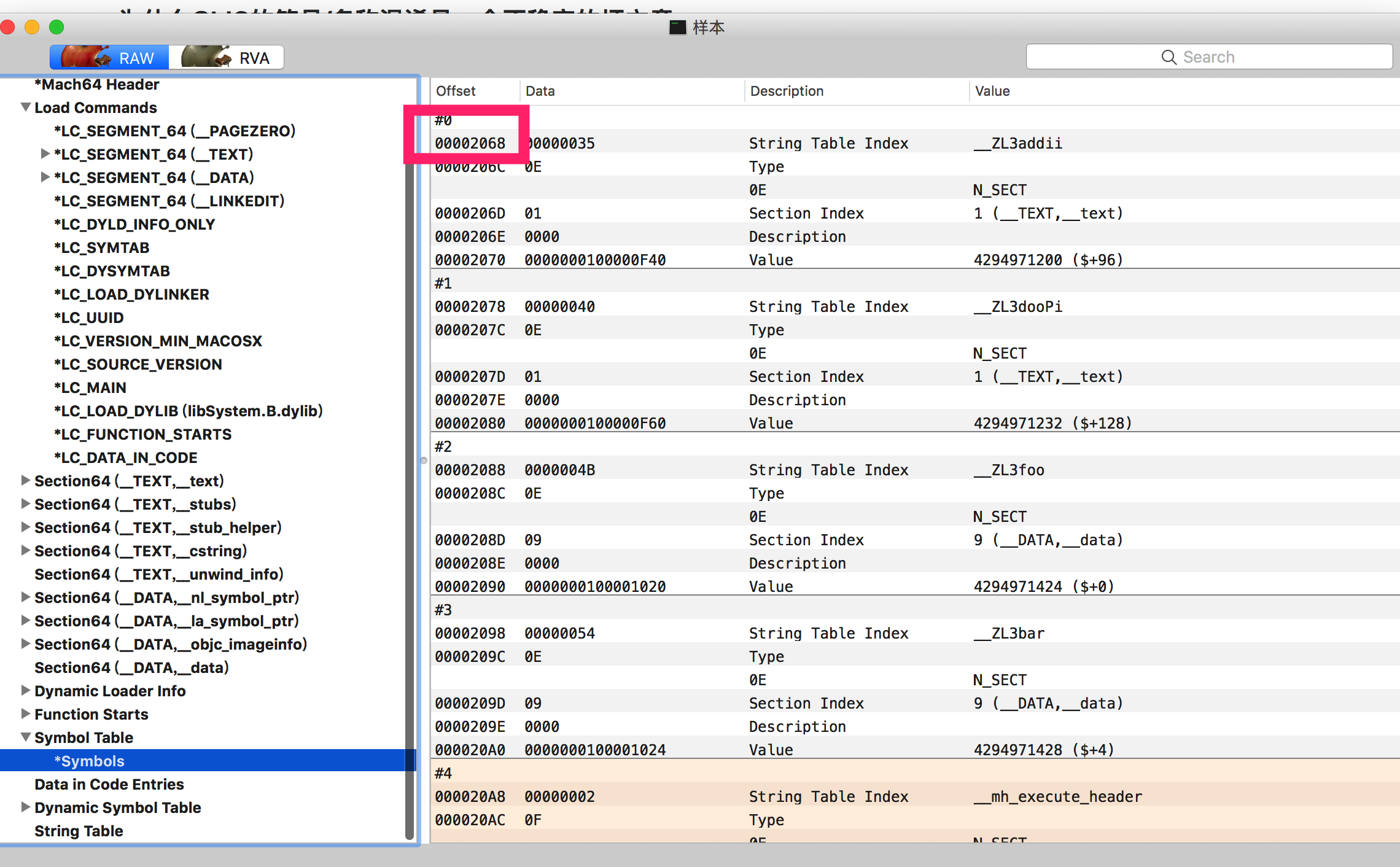
起始地址也是在0x2068,这个结构体的长度则由上文中
Symbol Table Offset下方的Number of Symbols决定。这里是8个符号。往右边仔细看这个符号表。
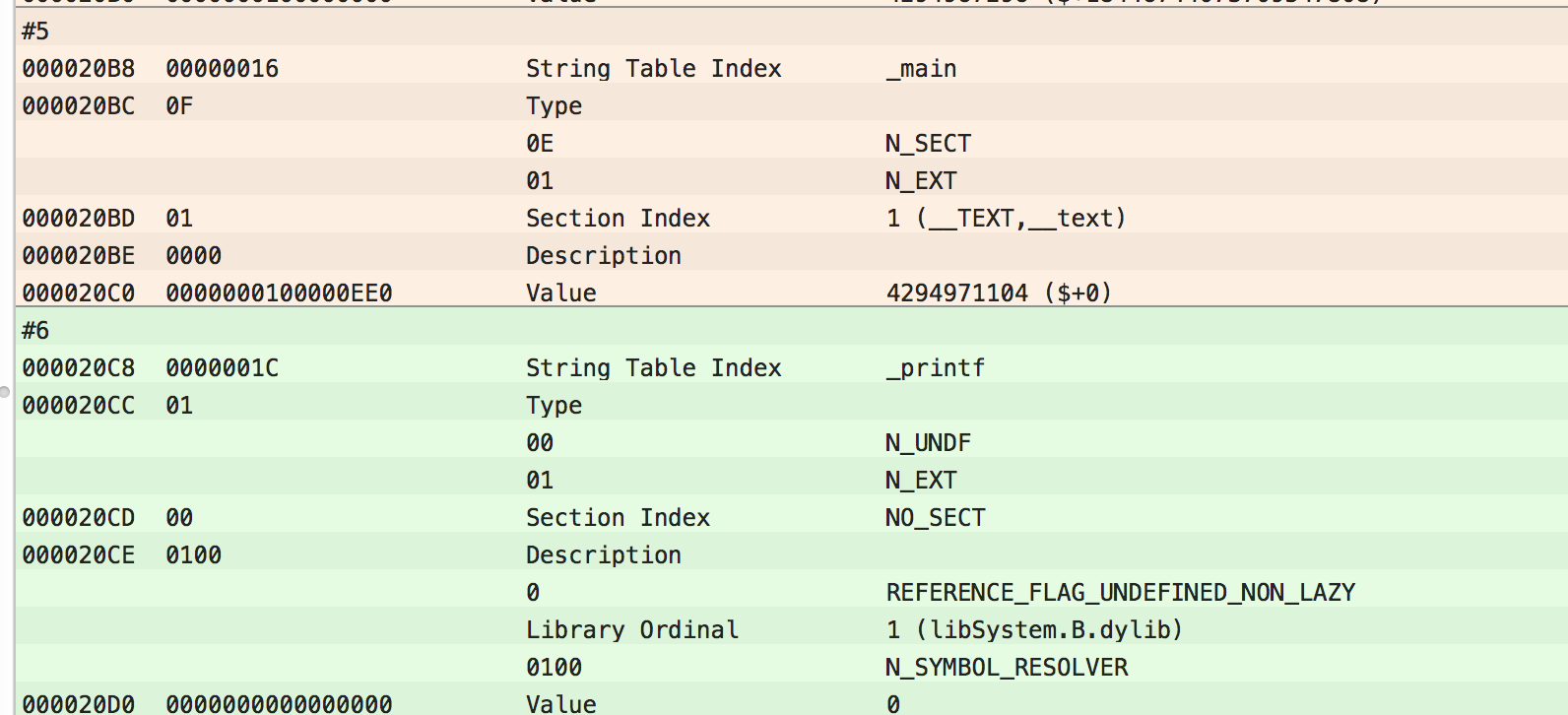
String Table Index指的就是这个符号的名字在符号表里的字符串表中的索引。比如这里的main是0x16。
下方的Type代表这个符号的类型,这里最重要的是
N_UNDF,有这个属性的符号代表外部符号,比如说系统函数等等都属于此列。可能不要动这些符号是一个好主意 而上面的比如说main等等都可以随意修改,比如说我们可以将索引修改为0,或者是随意交换索引,又或者是将索引修改为一个大数。为了有效的对抗反汇编器。这里我们将索引全部修改为0。 双击16进制的索引即可修改,完成后Command+S保存即可。
这时我们可以看到反汇编工具已经无法识别符号了:
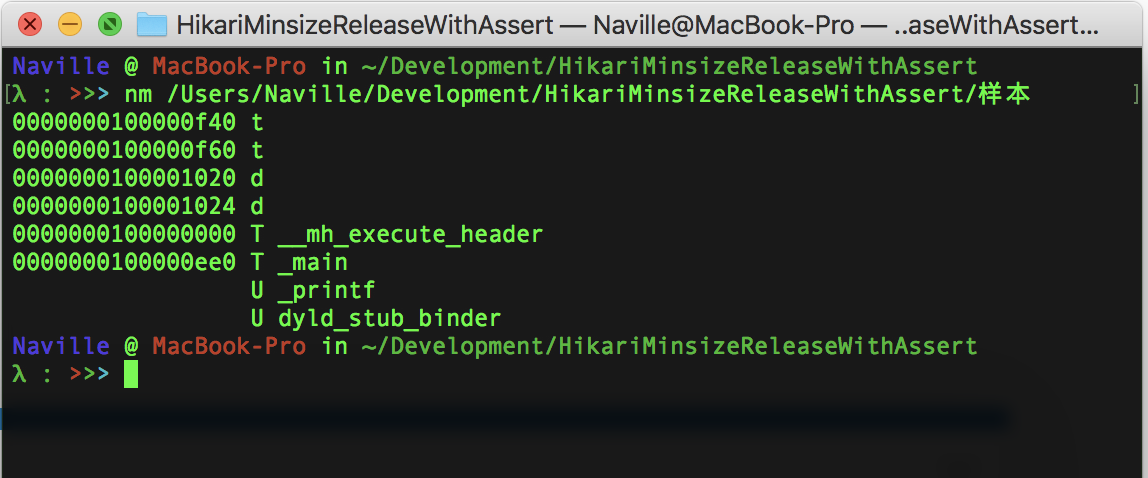
拉进Hopper:
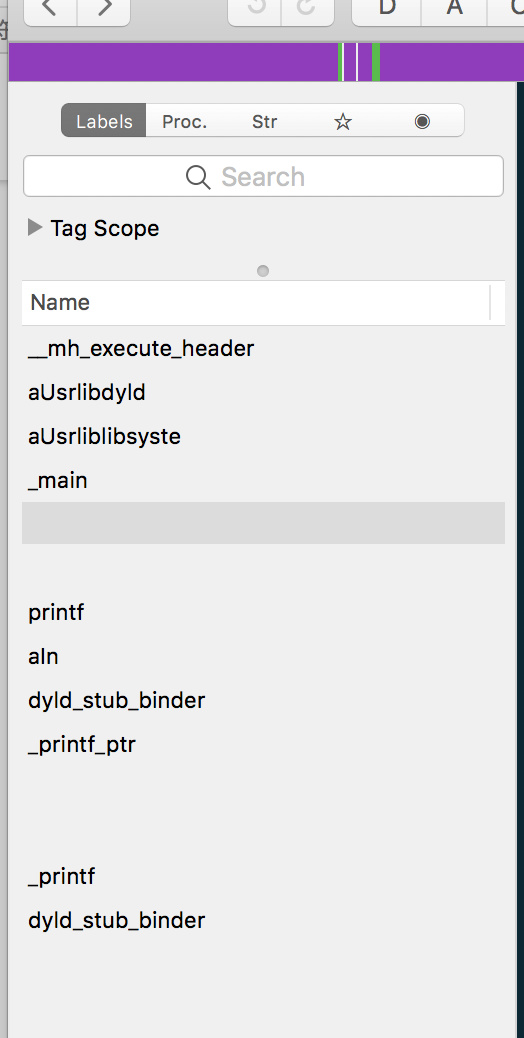
伪代码中函数名变成了空格:
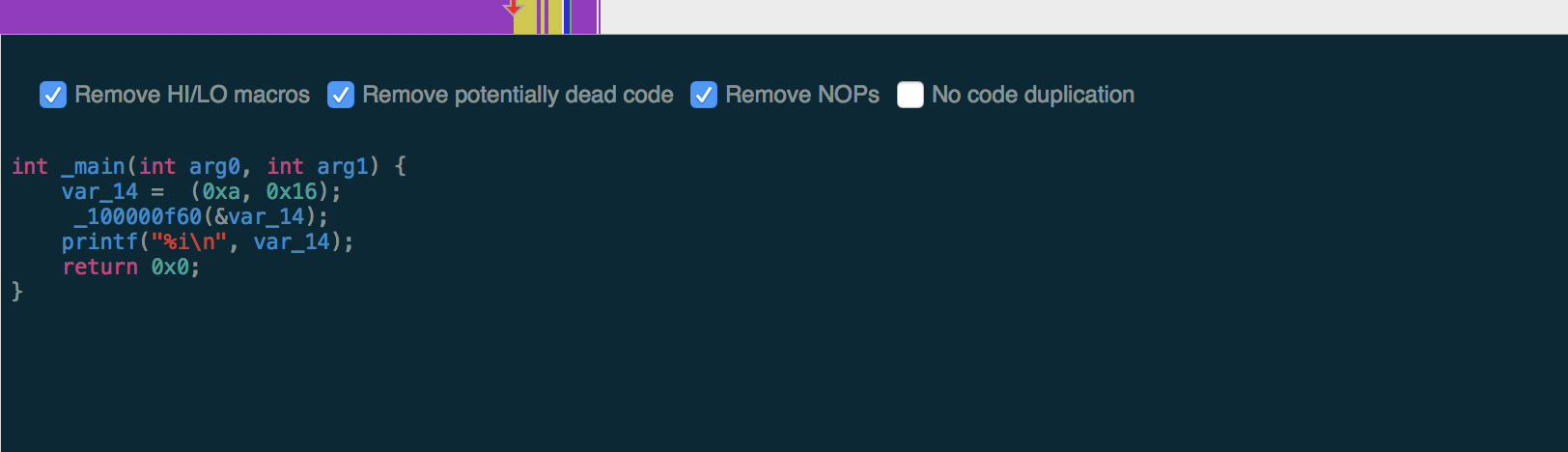
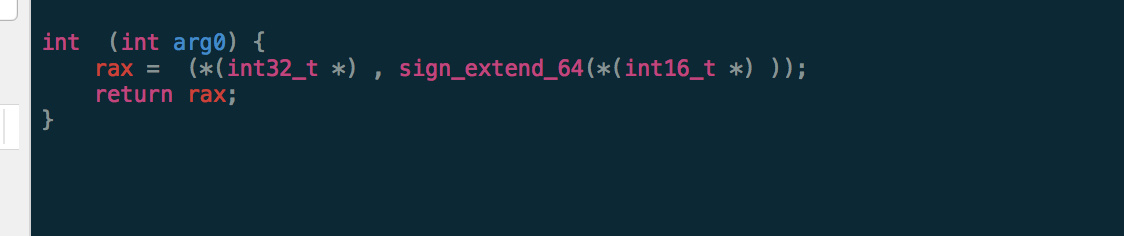
拓展
这里我们修改了索引,对于普通的hacker来说这已经足够了,但是对于稍微有一定技能的攻击者来说攻击者可能会尝试修复符号表的索引。所以我们可以修改刚才索引指向的地址的内容,而不是索引本身的数值。这类思路我觉得是比在LLVM层去做好很多的。这里说到的方法也可以全部自动化完成。具体的代码就不发了留给读者当作一次手动Parse MachO的练习即可。
下集预告
下一篇文章中我们将着重分析最近小圈子里比较火热的某(号称)虚拟化的iOS插件加固服务,并作出一些分析以及可能的对抗措施。看心情可能也会再写点其他基于LLVM搞事情的教程 ![]()
EDIT:
鉴于有人问那ObjC怎么手动重命名呢?
http://bbs.iosre.com/t/objectivec/8653/